CIO时代APP微讲座:北京邮电大学傅湘玲谈大数据与企业管理决策
CIO时代APP微讲座:北京邮电大学傅湘玲谈大数据与企业管理决策
2017-04-05 13:09:27 来源:CIO时代网 抢沙发
抢沙发
2017-04-05 13:09:27 来源:CIO时代网
摘要:3月24日,北京邮电大学软件学院副教授傅湘玲在CIO时代APP微讲座栏目作了题为《大数据与企业管理决策》的主题分享,具体从大数据在企业管理决策中的应用及企业做过的一些案例与体会展开。
关键词:
CIO时代APP
微讲座

3月24日,北京邮电大学软件学院副教授傅湘玲在CIO时代APP微讲座栏目作了题为《大数据与企业管理决策》的主题分享,具体从大数据在企业管理决策中的应用及企业做过的一些案例与体会展开。
关于大数据在企业管理中的应用我们要回答的有四个问题:第一,这些大数据说明了什么问题;第二,这些数据从哪里来;第三,我们得出了什么分析;第四,在结果中得到了什么启示。要实现大数据在企业管理决策中的应用,一方面是要有好的数据支撑,另一方面则需要经典的管理理论的应用。只有数据与经典理论结合起来,才可能会形成新的管理决策的应用和模型,这是对大数据与企业管理决策的理解。
分享五个案例:第一是基于海量的互联网数据的新产品开发决策;第二是基于海量互联网数据的竞争产品分析;第三是基于企业社交网络的员工潜力员工潜力测量研究;第四是利用公众博客文本进行公众幸福感测量;第五是基于微博在线数据的新闻线索挖掘。
一、基于海量的互联网数据的新产品开发决策
即如何在线评论中帮助企业的产品设计师更好地设计产品。传统的新产品设计一般是通过问卷的方式进行,用户买了产品之后,会留下很多评论,这种评论实际上代表了用户的需求,我们能否将这些用户需求转变为产品设计师的维度用户需求,从而改进产品设计。我们能否将经典的卡洛模型用在在线评论分析之中,从而实现智能及时地实现新产品的改进。如针对手机产品的评论所做的二次开发过程中,手机新产品开发过程中如何利用在线评论提取其需求,从而帮助设计师更好地改进产品设计。
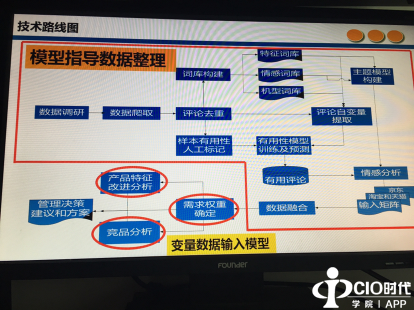
在上述的技术路线图中,首先是做一个数据调研,从京东、淘宝、新浪微博中提取我们需要做的手机数据,本研究中我们选取了十款需要分析的手机数据,从京东等网站上进行数据的爬取。获取到数据之后,在技术路线图中可以看到进行了数据的预处理,其中包括评论的去重,当然还有一项很重要的工作,即样本的有用性人工标记,其实对产品设计师而言,有些评论对产品设计师没用,但对消费者有用。做完样本的有用性标记之后,进行有用性模型训练,同时在大量的评论中构建了一个需要提取的特征、情感、机型,因此在技术路线中,构建了特征词库、情感词库、机型词库,在此基础上构建手机的主题模型,主题模型是指构建一个词对,比如手机的待机时间较长,接着进行情感的分析。做完这项工作后,再结合管理中的卡洛模型进行客户需求分析。卡洛模型中提到客户的满意包括基本需求,期望需求和惊喜需求,我们根据用户效用值的大小进行排序,得到用户的1)基本需求:版本、功能、外观、物流及售后、其他;2)期望需求:处理器及配件、屏幕、信号及发热、相机;3)惊喜需求:电池、价格、手感、系统。对此我们也提出相应的管理建议:对于基本需求,管理建议:保证符合服务标准,努力降低产品故障率和服务失误率;对于期望需求,管理建议:不单是考虑符合服务标准,而是如何提高服务标准。同样对于惊喜需求,管理建议:首先保证另外两类需求,开发新服务,增加新内容。
二、基于海量互联网数据的竞争产品分析
在产品评论中存在不同产品间的各种不同属性特征的比较,在此基础上我们提出了另外一个概念——产品在线声誉。产品的在线声誉分为产品美誉度和知名度。美誉度又从属性美誉度和属性权重两个角度进行考虑。就属性的美誉度而言,前面的过程中提取了手机的每个属性特征,如电池、屏幕、内存等,对每个属性都有一个评价的矩阵值,即一条评论中对某个属性的效用值,据此计算出属性的美誉度,接着对属性的权重进行计算,便可得出第i条评论对某个产品属性j的评价,从而测量出不同产品的在线声誉。在此案例中,我们针对四款手机进行了研究,分别为:华为、IPhone、三星、联想。
得出的结果大家在这个图中可以看到:
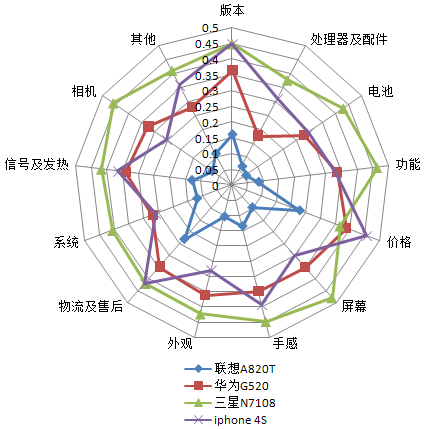
①三星N7108的各个属性的美誉度均在最外围(价格除外),即美誉度高;②联想A820T的各个属性的美誉度均在最内层,即美誉度最低;③iphone4S的大部分属性的美誉低于三星N7108(价格除外),却高于华为G520(相机、外观和屏幕除外),因此,从属性美誉度层面来看,三星N7108表现较好,最好能再适当下调点价格,联想A820T整体上都需要提升。
三、基于企业社交网络的员工潜力员工潜力测量研究
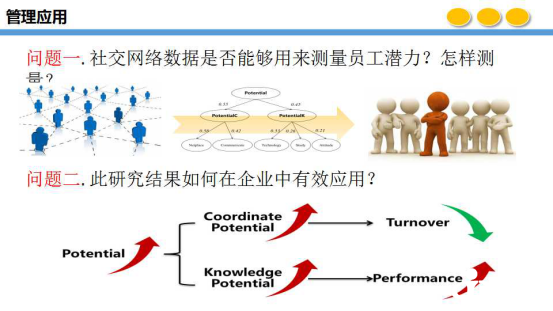
人资资源管理中企业员工的潜力研究一般也是多基于问卷进行,在这里我们也希望通过企业内部社交网络的数据来进行员工潜力的测量研究。我们选取了某企业社交网络中员工的社交数据,在此基础上构建了将员工的潜力分为了协调潜力和知识潜力两个维度。在此基础上进一步细化构建了每个细化的指标测量方法。通过对文本数据的分析与挖掘,量化测量出每个指标的值,从而进行员工潜力指数的测量研究。
 四、利用公众博客文本进行了公众幸福感测量
四、利用公众博客文本进行了公众幸福感测量
能不能利用文本进行量化的幸福感的测量呢?传统的做法是Watson教授提出来的PANAS量表,测量情感的幸福通过问卷的方式测量某个人的幸福感。但这种量表的方式无法实现大规模、可重复、无干扰的测量,也就是说,很多人在测试时未反映出真实的感情。因此,要实现无干扰环境下大规模、可重复的测量,则需要一个更好地可以利用海量客观数据的自动化方法测量公众的幸福,我们做了一个测量幸福感的模型,主要是从某一篇博文中出现的情感词数量及频率在整篇文章中所占的比例。其中有一个很大的问题,即中文的情感词库需要量化,传统的词库很多只有正面和负面,对每一个情感词并没有得分的比较,这是工作过程中很大的一个难题,英文中有公开的词库,经过多方努力,我们找到了Ren词库。
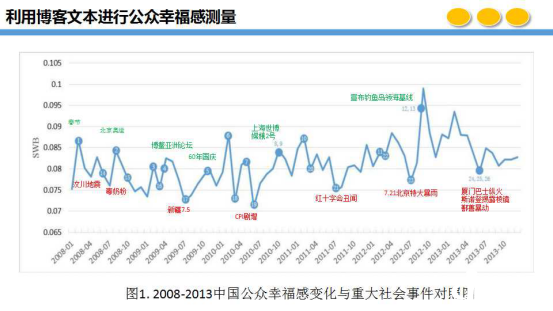
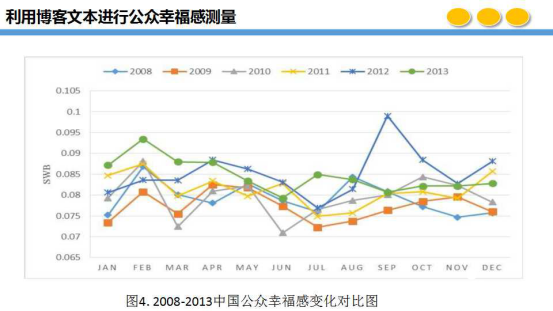
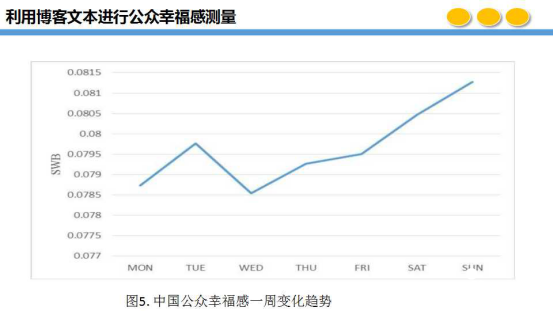
可以看出,我们模型的结果与实际情况是比较符合的,我们对历史已经发生的事件和现在模型的结果对比是可以对应的,这是我们对公众幸福感利用博客文本做的结果和重大事件的对比。同样,我们也做了周、年的比较,将六年中每年的数据进行对比后发现,每年的二月份是情感较高的,由于二月份有春节,春节后幸福感开始下降,同时十一也是如此。在周的对比中,周一较低,周二较高,由于工作比较疲惫,周三比较低,由于看到周末了,周四之后又开始上升。这是关于重大事件的对比、每年高峰低峰的对比以及一周的对比。
因此,在这个研究中,我们将经典心理学的主观幸福感测量(PANAS量表),利用互联网中大量非结构化数据设计了一个新的幸福感量化模型,实现了对社会公众幸福感的实时动态监测。
 五、基于微博在线数据的新闻线索挖掘
五、基于微博在线数据的新闻线索挖掘

目前来看,记者也是通过博客、社交网络大量的发现新闻线索,如通过微信群、QQ群、微博等发现有哪些热点发生,根据自己的知识判断,这有可能是一个值得深究的会成为一条新闻的消息,在此过程中可能浏览过一万条微博才发现一条值得调研和采访形成新闻的内容,我们称之为新闻线索。首先,我们构建了一个新闻线索的新闻价值模型,其中提高了线索的重要性、异常性和权变性。在构建了新闻线索后,我们听取了新华社、人民网的记者,以及一些新闻专家、公众的看法,进行了模型的改进,在技术路线图中可以看到,一方面是构建新闻价值线索模型,另一方面是从数据中找到新闻线索,在数据准备阶段,主要利用了微博,对微博事件进行了事件触发抽取、命名实体识别、时间表达抽取、事件后果抽取,由于在新闻价值模型中发现,这四个要素对新闻价值的评价是有用的,对这四个特征进行抽取后,构建了微博事件信息库和训练集、测试集,从而进行新闻价值模型的计算,这个计算过程中也进行了模型的计算和调整。以交通事故为例,通过这个过程可将某一天与所有交通有关的微博信息、新闻提取出来,并对其价值进行评分,在评分过程中,新闻事件的排名越前价值越高。对新闻记者而言,现在只需要看一千条微博便可以筛选出新闻报道的线索,减轻其工作量,从而更好地评价微博数据中可能存在的新闻线索。
以上便是五个方面的案例,其实数据是一个方面,经验管理模型的应用是第二个方面,将模型和数据结合起来,可以判断需要哪些数据、数据说明了哪些问题,以及这些数据分析如何应用到管理决策之中。
第三十五届CIO班招生
国际CIO认证培训
首席数据官(CDO)认证培训
责编:傅湘玲
免责声明:本网站(http://www.ciotimes.com/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等)版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。




