2016年8月13日,由北大信息化与信息管理研究中心、中国新一代IT产业推进联盟主办,CIO时代网、阿拉善盟旅游局、阿拉善盟文旅投公司承办,北达软、网加时代网、转型家、《金融电子化》协办的“第二届中国行业互联网大会暨CIO班十一周年年会&首届阿拉善峰会”在苍天圣地阿拉善成功举办。与此同时,互联网+金融分论坛在阿拉善隆重举行。来自金融领域的专家、知名企业代表和CIO学员们参加了此次论坛,在新一代信息技术的冲击下,就金融行业的最新技术进展、转型方向等内容进行了深刻的探讨与交锋。
中国新一代IT产业推进联盟云计算分委会副秘书长、OStorage创始人兼CTO李明宇发表了题为《分布式存储系统的建设策略》的主题演讲。以下为演讲全文实录:
谢谢邵总,非常荣幸今天能够由姚老师引荐给大家做这个分享,我之前在中科院工作,后来创业了,这中间做了几年OpenStack,也是因为做OpenStack这个事情,非常有缘来北大CIO班讲过两次OpenStack,也加入了新一代IT产业推进联盟做了一些事情,今天的这个分享,也是作为联盟云计算一员的身份来分享,所以今天讲的主要是偏技术和发展趋势方面的,跟公司的事情关系不大。
以前有机构做过一个预测,从2010年-2020年,十年全球数据量会从400EB增长到13ZB,而我们现在正处在这中间,我们可以明显的感觉数据量在快速增长。增长过程中出现了几个特点:数据量很大、增长迅速,这也是我们在大数据时代反复提的两个特点。另外一点是,在如此大体量的数据中,90%的是非结构化数据,比如在金融领域,在此之前,金融领域处理的数据基本都是结构化数据。但是近年出现了越来越多的图片等非结构化数据,而且量非常大。
刚才所讲的是跟大数据时代相关,还有一点是跟互联网+相关的,就是支持高并发。为什么?两个方面,一方面有些数据我们希望直接从数据中心里面访问,现在服务器数量越来越多,做虚拟化以后这种虚拟主机的数量就更加的多,而且虚机用得好的是动态创建动态销毁,所以他们访问存储时对并发的要求比较高;更进一步来说,我们希望有些终端,手机、浏览器直接访问存储里面的数据,因为有些数据从存储后端出来的时候很多是不需要经过复杂处理的,比如淘宝上的图片,我们会希望它能够从存储系统里面直接访问,不需要占用数据库的资源。这些事情对于传统存储来说是技术难题,也是催生分布式存储技术发展的非常重要的动力。
我们前两年一直说数据架构转型,有人将这个转型比做由宠物模式向牲口模式的转变。在宠物模式下,数据中心里的设备像一只一只现实的宠物一样,一眼看过之后都知道是干嘛的,而牲口模式下,清一色的标准服务器,就比如内蒙古牧场里面的牛,看了之后都分辨不出来哪头是哪头。但是他们的功能在数据中心里面通过软件定义,而且任何一个服务器如果宕机的话,在宠物模式下就好比家里养的小猫小狗如果生病了,主人会非常心疼,赶快给它治好,但如果说是牲口生病了可能我们第一时间想到的是把它隔离不要传染给别人。对于数据中心来说也是一样,那我们怎么实现从宠物模式向牲口模式的转变呢?很重要的一点就是借助于分布式技术。
再说到数据存储的话题上来,说到分布式存储,最先想到的就是Hadoop,他的底层存储是HDFS,起源于Google的GFS。
关于它的架构我们不去细说,大家都知道,它有个特点,就是为解决搜索引擎后端的大数据集存储的,Google把很多小的东西拼起来,拼成一个大文件存和取,读出来可以通过MapReduce做分析。所以它对大文件的支持非常好,用起来体验就像这个图这样:
但实际上在今天很多的场景中,我们会有很多的小文件要存储,拿电商来说,比如某宝上一个网店的图片,往往在网店开了几年之后就会有上万张图片,这个数量可能是出乎人们意料的,每当有新产品推出后,店家就会上传新产品的图片,但一般不会删掉以前的图片,长此以往,某宝图片总量就极其的巨大,这就是典型的海量小文件存储。如今的金融领域也面临着这种状况,后面我会举几个例子。这种海量小文件存储对于HDFS来说,它的负担就非常重。后来人们就想办法借助MapReduce来解决HDFS存储海量小文件问题,但是毕竟要借助MapReduce做计算,会引入一些新的问题。当然我这么说并不是在黑HDFS,只是说不同的分布式存储应用于不同的场景。这实际上就反映了大数据存储的另外一方面就是 海量小文件存储。
下面在讲一些更具体的技术之前,首先想跟大家分享一下,我认为的在存储系统里面,衡量存储系统三个很重要的东西。提到存储系统,大家会想到:IOPS是多少、吞吐量是多少等性能指标?当然,性能固然是很重要的一方面,但是我今天要说的这三个东西同样是非常重要的,那就是三个ability,第一个是Durability持久性,这个反映的是存储系统的可靠性。
比如某个云存储声称他的数据存储的可靠性是16个9,实际上并不是说可靠性,他说的是Durability,但是对于Durability这个词,好多人接受不了,不知道你在说什么,所以通俗就说“可靠性”。但实际上持久性的表述是更准确的,什么意思呢?通常情况下,我们用平均无故障时间和平均故障修复时间来衡量系统的可靠性,但实际上对于分布式系统来说不存在这种情况,系统一直在运行,中间难免有节点出现链路故障但不会导致整个系统故障,如果导致整个系统故障,这个事情就很难弄了。所以我们不应该用这个来衡量系统的可靠性,那怎么衡量呢?数据存进去不丢的概率是多大,这个就是Durability。但是同一个分布式存储系统,在不同人手里因为采用了不同的运维水平和运维策略,能达到的数据持久性是不一样的,这里面还有成本因素。所以数据持久性有另外一个通俗的理解,就是在你坏多少东西的前提下保证数据不会丢。比如说最多坏两个节点数据不会丢、最多坏一个节点和一个盘数据不丢、最多坏一个数据中心数据不丢等。好多分布式系统都用这种方式来标书,包括HDFS,因为有机架感知,所以中大规模HDFS集群通常可以做到坏一个机柜或者坏任意两个节点数据不丢失。
第二个是Scalability,它指的是什么?这也是分布式存储非常重要的东西。比如说我今天有10T的数据,下个季度可能变成30T,到明年可能变成200T,后年可能是一个PB,那么以这种速度增长下去的时候我对存储系统进行扩展,是不是能够很容易实现。
第三个Availability,这一点很有意思,它以前经常用来衡量互联网服务,比如系统上线以后,一个服务的在线时间除以系统上线后的总时间就得到可用性,这反映的是我们需要使用这个系统时它能够多长时间多大概率的可用。现在我们说存储系统里面有一个指标是数据的Availability,什么意思?比如刚才说的高并发访问,往往会遇到这样的情况,就是数据就在那,但读的时候就是读不出来,并发量上去的时候。 这时候我们说这个系统,说数据丢了好象也不是,但是这个数据Availability出现问题。所以这是我们所说的今天衡量一个存储系统,特别是分布式存储系统发展以后很重要的三个方面。
下面就举三个存在这些问题的场景。
首先在金融领域,大量的票据需要做电子化,出现了大量的图片。这些图片的大小在多少呢?根据不同的采集手段、不同的图片质量,大小不一样,基本是在这个100k-100M之内这个量级。这让HDFS存储系统存储的话就显得很吃力,因为HDFS是把文件切成64MB或128MB的小块往下存。如果银行以后取消网点该怎么办理业务呢?这就需要通过远程方式办理业务,经常要用设备拍照,同时就会产生大量图片要存储,还有就是可能要存储声音,这些都是典型的小文件存储。有一个对象存储用户,他们不断地在互联网上用爬虫爬取一些新闻、图片、报道或者其他的一些数据,这些数据也都是海量的典型小文件。我们假设爬虫一秒钟爬一个文件,一天24小时、一年365天会爬多少文件下来?三千多万。系统里也不可能只有这一个业务运行,一个爬虫也不可能一秒钟只爬一个文件,往往不是这样的,这个量往往是成倍的,然后他还有其他业务也需要用这个存储系统,所以他一年下来可能就是几千万甚至上亿的文件,这个量是之前没有考虑到的,在这个数量下,传统文件系统,负载压力一上来,就有可能文件读不出来,也就是说,数据的Availability会遇到问题,所以这就是传统文件系统遇到的问题。还有其他类似的问题,比如说有的用户希望在文件系统里面搞一个100TB的volume,这么大的一个volume,放到一个文件系统里面,意味着一个共享目录存这么多文件,传统文件系统肯定会遇到问题。
对于这个问题有没有办法解决呢?答案肯定是有的,这就是分布式对象存储。对象是什么?通俗来说,数据存到文件系统里面就叫文件,存到对象存储里面就叫对象。所以对象就可以理解为传统意义上的文件。它主要就是解决传统文件存储面对海量小文件场景下的一些不足。另外它能够具有非常好的Scalability,并且在海量小文件的情况下还可以保证很好的Availability。当然前面说的Durability,数据存下来不丢,这是常规要求,任何存储系统都必须达到的前提,所以在这个地方就不去强调了。
对象存储还有另外一种更容易理解的说法就是类AWS的S3,与亚马逊S3类似的存储,特点是抛弃了目录树,为什么?因为当文件数量多了以后,目录的管理就会变得很困难,很大程度上由于它要维护树型结构,因为树型结构的存在,会导致很多事情的计算复杂度很高。所以我们索性不要目录树,就直接用桶来存,扁平的结构。相对应的另外一个是在现实应用的时候,我们越来越少的依赖目录去对数据进行分类和管理,而更多的是利用检索的方式,利用数据库管理。通过数据库检索,得到所有文章,再通过索引从后端存储中把数据读出来。所以现在分级目录的作用越来越弱。一方面它的作用越来越弱,另外一方面使用目录会带来一系列的问题,索性就不用了。所以为什么S3没有目录,他就是对象存储,根本原因在这里。另外一方面,为了支持文件的共享,就是这一秒钟是它要读、下一秒是另外一个要读,这个时候怎么办呢?对象存储使用RESTful的接口,使得每个对象请求之间都是相互独立的,没有传统文件系统接口繁琐的操作,所以这也是对象存储的特点。
这里插一句,说到对象存储,我其实更愿意说S3存储或者类S3的存储,为什么?因为对象存储在06年以前不是这个意思,指的是另外一个意思,所以说到对象存储到底说的是什么,其实要看上下文,这里就不做过多的解释了。我们现在要想实现这个事情是有开源的工具可以借鉴的。因为今天只讨论技术本身,所以不去讲公司产品,而是说我们用开源的软件自己做。这个开源软件是什么呢?就是OpenStack Swift对象存储。在国内外也有很多用户了:
这是我们根据公开的信息能够了解到的国内外的用户,当然不止这些。所以说,在运营商、电商、基因、生命科学等领域都存在OpenStackSwift 对象存储的身影,当然也包括公有云。
下面我就简单说一下它的六个特点:
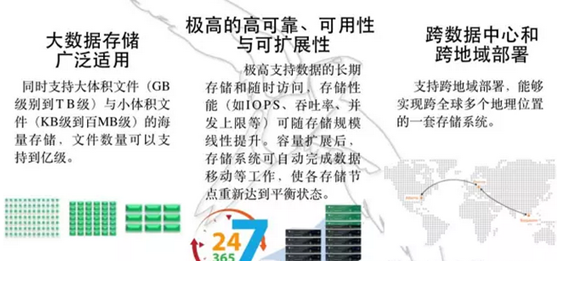
首先是大数据存储广泛适用。什么意思呢?就是它可以同时支持海量小文件和大体积文件的存储。现在的很多存储系统,比如某宝为了解决图片存储问题,自己开发的TFS,TFS要存大文件就不好办了,再比如前面说的HDFS存大文件很好,存小文件就有问题。我们现在希望能够存储,比如说遥感卫星的数据,既有大体积文件也有小体积文件,一幅遥感图像体积可能是GB级的,但是经过处理的数据产品,体积并不是很大,还有缩略图都要存进去,这个体积就更小了,要一套存储系统都搞定,这个OpenStack Swift是可以支持的。
这里提一句,因为OpenStack Swift比其他技术出现的晚,所以在技术上比HDFS、TFS肯定是要有进步,所以这是它的一些特点,我觉得根本原因是因为整个时代在往前发展会带来技术上新的特点。
另外就是刚才提到的三个ability,这三个ability它都可以做的比较好。具体的原因不多说了,中间有很多东西,比如说基于一致性哈希但是又对它做了一些改进,另外整体采用share nothing架构,这样的话你的存储系统里面任何一个节点出现问题、任何一个部分出现问题,都不会导致整个系统的可用性问题。它里面数据存储的可靠性,也就是Durability也比较高。
还有一个,也是比较有意思的地方,它可以实现跨地域组成一个存储集群。拿银行来说,我们要把存储做成两地三中心。以前两地三中心怎么做呢?搞三个存储集群,想办法同步复制、异步复制,搞很多事情。但如果用OpenStack Swift,则就不用操心这个问题,因为它本身就可以实现跨地域的存储集群。也就是说它是“一个”存储集群,并不是以前意义上所说两地三中心搞三个存储集群,然后互相之间怎么同步。一个跨地域的Swift存储集群里面,数据怎么同步,它有自己的管理办法,用户只需要知道怎么使用,只需要把放在三个数据中心里面的节点按照它规则进行配置,其余的事情Swift自己就可以自动完成。
今年比较火的一个事情是对象存储的Erasure Codes纠删码,这个Swift很早就支持了。传统意义上分布式存储都用多副本的方式去存数据,一份数据存三个副本,比较浪费存储空间。怎么办呢?有人就发明了Erasure Codes,其实它原来是通讯领域的事情,但是现在已经应用到了存储领域。因为纯粹从数学上建模的话,存储系统其实是一个信道,一边将信息输入进去,另一边读的时候就是把信息传出去,如此说来,存储整个就是一个信道,所以可以将Erasure Codes应用进去。它可以降低存储空间的使用。另外还有就是一个Swift集群可以支持多个资源池,这里面涉及到刚才所提到的我们建了两地三中心以后,有些数据,比如测试开发系统的数据并不希望它都要三个数中心都存,那我们可以控制建立不同的存储资源池,有的存储资源池跨三个数据中心,有的存储资源池只在某一个数据中心里面,有的存储资源池把数据都放在SSD上,追求高性能,有的放在磁盘上,甚至我们现在做一件事情,集成带库,这样的话,热数据、温数据、冷数据,可以通过划分不同的存储资源池把它放在一个集群里面去存,这就很方便了。
另外还有一点,也是我认为的整个OpenStack做的最好的一点,就是插件式架构,当然OpenStack Swift作为其中一个项目也不会例外。OpenStack产业在全球看来真的是很震撼,这次4月份去美国参加OpenStack峰会的时候,会议人数达7500多人,特别大。每届峰会现场都会有一个展台,那个展台什么都不干,放一堆乐高在上面。什么意思呢?OpenStack一个思想就是希望像乐高一样,都是插件,用户能够用插件组装丰富多彩的自己想要的东西。其实对于OpenStack Swift来说也是一样,很重要的一点就是可以通过middleware,也是一种插件,实现对功能的扩展。比如说我们在金融领域里面要做数据加密,那怎么办?是不是要先搞一个东西把数据加密了,再想怎么存到存储系统里面?不需要,我们通过一个插件就可以在数据写入时加密,数据读取时自动解密。这样存到Swift集群里面的全部都是加密的数据。对于认证,金融领域中基于用户名和密码的认证是不够的,需要用U盾,甚至是生物识别系统,例如用指纹、虹膜做认证,在Swift存储集群中,我们可以通过插件实现多种不同的认证方式。不同的数据要求用不同的认证方式才能访问,这个也可以通过插件来进行扩展。还有数据预处理,如不良信息扫描,很多网盘里是要用的,可以在数据上传时通过插件来实现。用插件能够让这些功能跟存储系统融为一体,不用再单独搞一个东西出来,还要去维护它,另外一方面也不会影响到存储系统原有的代码,这是插件的好处。既然能把图像做预处理,不良信息扫描或者加密,那能不能顺带手把OCR给做了?实际上答案是肯定的,如果要做OCR的话,做个插件放进去就可以了,而且可以很好的与存储对接,其实很多种功能都可以通过插件扩展,这个也是Swift存储系统具有的特点。
上面这些是我列举的一些比较有特色的,当然一些分布式存储的基本要求,数据可靠、扩容时不能影响数据读写,这些基本的东西Swift也都是具备的。
今天因为时间有限,所以只能讨论这些,但是后面还有别的问题,也都是我们现在在做或者说是建一个分布式存储系统需要考虑的。比如说对象存储,和传统文件系统的兼容,企业里面都有一些以前开发的应用,不可能说都做改造,所以向前兼容是很重要的,我们现在不仅可以兼容标准的传统文件系统,还可以兼容HDFS,这里没有时间展开说了。另外就如何发挥万兆网和SSD的性能,还有选用服务器的事情,是不是存储服务器选用盘越多的服务器越好,盘越多的服务器越适合做存储?我觉得答案是不一定的。我认为的是容量和节点数量需要有一个适当的匹配。当容量比较大的时候,节点里盘的数量多一点没问题,因为这一个节点宕了对整个集群影响不是很大。
比如一个72盘位的服务器,还是竖插的,只有把它断电拔出来才能维护。像这种情况,如果一个节点挂掉了,可能半个BP的裸容量就没了。如果规模不够大,虽然你做了分布式,难道半个BP没了就一定没有影响吗?我认为整个规模上去以后,可以适当的扩大每个节点的盘的数量,但不是一上来就选用一个节点挂盘非常多,然后少用几个节点,没有必要。所以说保持一个适当节点数量还是很有必要的。然后就是刚才说到的纠删码Erasure Codes,听起来很美好,节省了存储空间,但是用的时候会引入一些新的运维的问题,需要考虑到。比如说以前的数据恢复可以是延迟恢复。有一个节点宕机或者有个盘坏了,没有必要马上把盘上的数据恢复出来。为什么?因为有时候这个节点可能是因为某种临时性原因出现问题了,比如说是服务器死机了,那他就能很快地恢复,没有必要说赶紧把数据拷一个副本在别的地方,但是如果用了纠删码这个情况是有变化的,因为如果你不恢复,读的性能就会受到影响,网络的压力和IO压力也会变化。这个是需要考虑的问题。怎么去做,如果大家有兴趣的话咱们可以以后再找机会讨论。
最后强调一下,今天主要介绍的是OpenStack Swift对象存储,因为我觉得这个比较新颖,而且是针对我们现在大数据时代和互联网+新衍生出来的一些需求,恰恰解决了咱们这次年会主题里涵盖的一些问题。另外还有很多非常优秀的分布式存储系统,今天就不能一一介绍了,但也都是比较有价值的。
谢谢大家!
第三十五届CIO班招生
国际CIO认证培训
首席数据官(CDO)认证培训
责编:李明宇
免责声明:本网站(http://www.ciotimes.com/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等)版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。