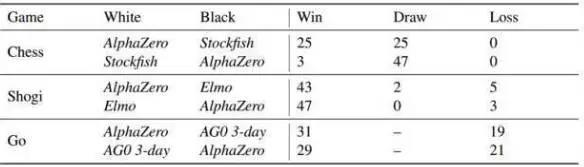
上周,由强化学习加持的AlphaZero,把DeepMind在围棋上的突破成功泛化到其他棋类游戏:8小时打败李世石版AlphaGo,4小时击败国际象棋最强AI——Stockfish,2小时干掉日本象棋最强AI——Elmo,34小时胜过训练3天的AlphaGo Zero。
对于这个不再需要训练数据的AlphaZero,有人将其突破归功于DeepMind在实验中所用的5064个TPU的强大计算能力,更有甚者则将整个深度学习的突破都归功于算力,瞬间激起千层浪。
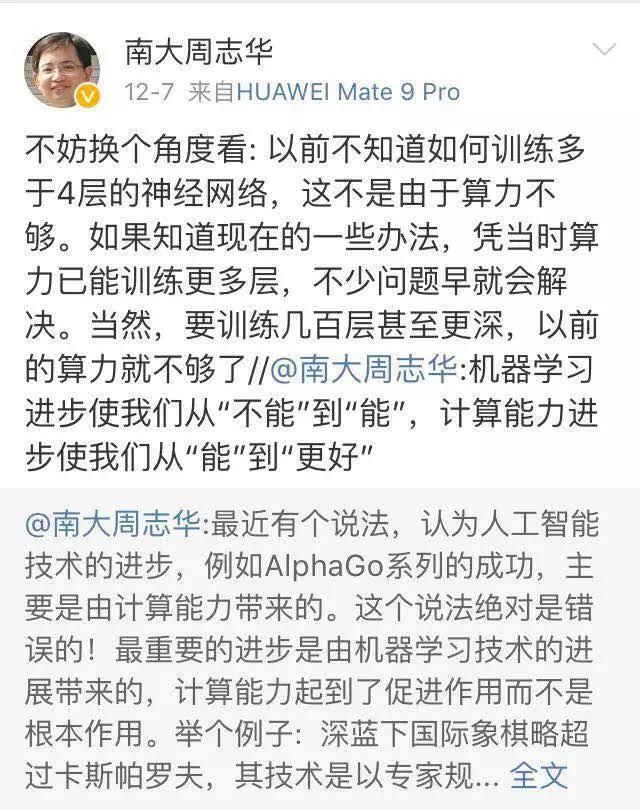
很快,南大周志华教授就在微博上指出,这个说法是绝对错误的!
“最重要的进步是由机器学习技术的进步带来的,计算能力起到了促进作用而不是根本作用。”他的全文是这样的:
对此,中科院计算所的包云岗研究员则表示,“算法进步和计算能力进步对今天AI都不可或缺”,二者相辅相成。其中算力提升的作用则表现在运行时间减少、功耗降低、开发效率提高这几大方面,进步相当显着:
此后,周志华教授则把该问题进一步定性为:“机器学习的进步使我们从‘不能’到‘能’,计算能力的进步使我们从‘能’到‘更好’。试图抹杀前者的作用,认为一切都是计算能力提高带来的,是错误且危险的”
交锋的双方均有数据来做支撑:一边强调算法效率所提升的3万倍;另一边强调计算能力所提升的1万倍,特别是并行计算能力所带来的200万倍提速。
随后,杜克大学副教授陈怡然也加入论战,在他那篇《有关最近深度学习的两个争论》中,陈教授认为计算能力的提高对于深度学习的发展是有很大贡献的,他特别提到了Hinton老爷子和李飞飞教授的观点:
之前很多文章说到深度学习这波高潮的标志性起点是2006年Hinton那篇Science文章。在这篇文章里Hinton其中第一次明确提到计算能力是其研究能成功的三大条件之一:“provided that computers were fast enough, data sets were big enough,and the initial weights were close enough to a good solution”。2014年IBM TrueNoth芯片的发布会我受邀请在现场,当时刚刚加入斯坦福不到两年的李飞飞在她的邀请报告中明确提到CNN等深度学习模型的架构和1989年被发明时并无显着区别,之所以能广泛应用的主要原因时两个主要条件的变化:大数据的出现和运算力的提升(大约提高了一百万倍)。
这里提到的Hinton老爷子那篇文章,是他和当时的学生Russ Salakhutdinov(如今的苹果AI主管)共同署名的《Reducing the Dimensionality of Data with Neural Networks》一文。他们在文中提出了一种在前馈神经网络中进行有效训练的算法,即将网络中的每一层视为无监督的受限玻尔兹曼机,再使用有监督的反向传播算法进行调优。
这一论文奠定了反向传播算法在深度学习中的支柱性地位,并给出了深度学习成功的三大基石:计算能力、大数据和算法突破。
“事后来看的话,利用大数据训练计算机算法的做法或许显而易见。但是在2007年,一切却没那么明显……”这是李飞飞教授2015年在TED演讲时所做的总结。到2009年,规模空前的ImageNet图片数据集诞生了。其中包括1500万张照片、涵盖22000种物品,仅”猫”一个对象,就有62000多只长相各异、姿势五花八门、品种多种多样的猫的照片。
这一“猫”的数据集,为吴恩达2012年在Google Brain实现“认出YouTube视频上的猫”的成果奠定好了基础。
同样在2012年,基于ImageNet的图像识别大赛,Hinton和他的学生Alex Krizhevsky在英伟达GPU上取得视觉领域的突破性成果。据此,英伟达研究中心的Bryan Catanzaro跟吴恩达合作研究GPU,结果证实,12个GPU的深度学习能力相当于2000个CPU的表现总和。
而后,英伟达开始在深度学习上发力——投入20亿美元、动用数千工程师,第一台专门为深度学习优化的GPU被提上日程。经过3年多的开发,直到2016年5月正式发布,才有了老黄GPU的深度学习大爆炸。
简单来从时间线上看,确实是先有算法上的突破,而后才有更大规模的数据集,以及专注于深度学习的GPU硬件。把这一切归功于计算能力的提升,似乎确有免费替老黄卖硬件的嫌疑。
但是看具体的进展,Hinton老爷子2006年的算法突破终究离不开当时的数据集与计算机硬件。毕竟,Pascal语言之父Niklaus Wirth早就告诉我们,算法加上数据结构才能写出实用的程序。而没有计算机硬件承载运行的程序代码,则又毫无存在的意义。
回到AlphaZero的问题,它的突破到底该归功于算法还是算力?
我们知道,AlphaZero是AlphaGo Zero的进一步优化,后者的目的是让电脑不学人类的对局也能学会围棋,这是AlphaGo彻底打败人类之后,DeepMind赋予其围棋项目的新使命。尽管不使用任何训练数据,AlphaZero却用到5000个TPU来生成对弈数据,而用于模型训练的TPU数量仅为64个。
而这里的一切投入,不过是DeepMind之父Demis Hassabis想要解决通用学习问题、超越人类认知极限的一个注脚。如果没有DeepMind大量的人力物力投入,蒙特卡洛树搜索算法和GPU并行计算可不会自发地进化成AlphaGo并打败李世石、柯洁,如果没有更进一步的投入,AlphaGo Zero也不会自己就能学会围棋,AlphaZero更不会自动把它的围棋能力泛化到其他棋类上。
也就是说,AlphaZero和它的强化学习算法、它的TPU运算集群,是由它背后David Silver、Demis Hassabis等人的疯狂努力才组合出最佳的效果,向解决通用学习的最终问题又迈进了一步。
而撇开这个全景,单点去谈算法和算力之于深度学习孰强孰弱,就有点像是抛开鸡的整个物种的进化,而去谈先有鸡还是先有蛋的问题……问题只是,到底大家是关心鸡的祖先多一点呢?还是关心餐盘内的鸡蛋、鸡肉好不好吃多一些?
第四十一届CIO班招生
国际CIO认证培训
首席数据官(CDO)认证培训
责编:kongwen
免责声明:本网站(http://www.ciotimes.com/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等)版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。