
这个观点颇为极端,但我们特别认同buzzword的危害。Buzzword其实是被绑架了的词汇,出现后迅速被媒体和圈内人热炒,从业者或营销人员也顺势跟进,再加上创业者的前赴后继和以及一点点toVC策略,一同引发了群体性狂欢。
但由于没多少人真的去仔细研究这些buzzword背后的东西,最终导致的结果是吹捧的时候吹到天上去,而只要风向稍有变化,就玩命了去踩。这几天关于MagicLeap的新闻这是这一点的最好写照。
前一阵子区块链很火的时候,USV的大佬FredWilson怒了,他在一次活动上说,许多dumbmoney的思路其实就是:这个叫区块链东西这么火?那我也得赶紧搞点才是。
Oh shit,Ineed some blockchain.Where do I get some blockchain?
—FredWilson,Union Square Ventures
看过前几篇文章的读者会发现(参考:在我们等待下一个风口的时候),我们对于所谓风口或者buzzword的态度很一致。绕过无休止地吹捧和不切实际的预期,我们能做的只有保持冷静,挖掘出其真实的面貌,然后尽可能在谈一件事情之前,先弄明白这件事情本身。
AI就是一个典型的例子。当我们说AI的时候,我们在说什么?
Winteris(not)coming
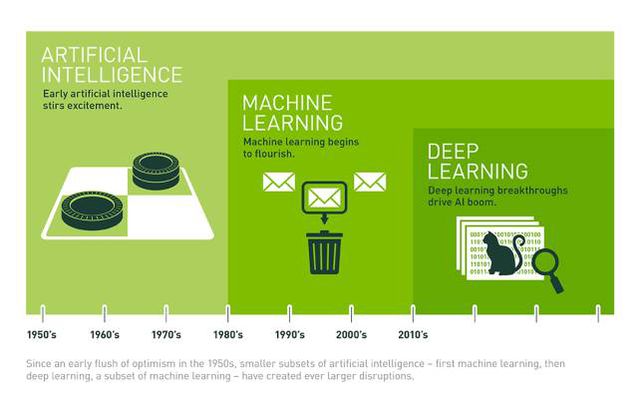
AI的概念最早被提出是在1956年。从那时到现在的几十年里,AI领域多次给出了美妙的承诺,与之相伴还有大批的科幻作品和他们塑造的深入人心的AI形象。然而这些承诺不断在勾起人们的希望后破灭。随后,就是一次次人称AIWinter的冷却期。这个词源于NuclearWinter。考虑到1950年代的时代背景和冷战引发的人们对NuclearWinter的恐惧,AIWinter这个称呼本身就说明了当时人们的失望之情。
鸟与空气动力学
早期的AI是一种自上而下的思路。和今天大部分写程序的思路类似,实质上是通过许多类似If…Then…的命令,给电脑制定一套规则。例如最早期的应用:给翻译机器人写明大量语法规则;或者人为规定出较小的决策空间(Micro-world),在这个有限可控的空间里面,为机器人编写行为规则;或者在一个狭窄的领域里面模仿专家的思路,构建一个专家系统(Expert System)。
工程师希望这套规则的完备程度足够高,可以让AI应对不同的环境,例如让机器理解不同语境下句子的含义。
然而,这种思路几乎没办法应对实际情况。语言中存在大量的情景以及不同情景下微妙的差异,这时候哪怕用一整个团队专门为机器写语法,效果仍然很差。在一个狭窄领域下的专家系统也丝毫不能帮助人们打造其他领域下的AI。离开了人为限定的小空间,机器人的表现就会马上出现大量错误。
本质上,这种自上而下的思路源自人们对AI的一种基础设想:人类智能最突出特征是逻辑推论能力,那么把这些推论方法,例如语法规则和决策方法写入AI程序是非常自然的选择。吴军博士把这种方法称为「鸟飞派」,意指人类最早通过观察鸟是怎么飞的,进而进行模仿。这当然是不成功的,直到后来人类对流体力学的掌握,才让人类飞行的梦想迈出第一步。
毕竟人类想要的是飞行,而不是成为鸟类。
这种思路现在虽然已经变成了弱势,但要知道直到1997年,击败国际象棋大师Garry Kasparov的IBM深蓝电脑使用的还是这种传统的AI技术。2011年,成为Jeopardy游戏冠军的IBM Watson使用的也是传统的AI技术。
自下而上的思路:人工神经网络
今天,AI快速发展的基础是人工神经网络(Artificial Neural Network)。与上面提到的思路相比,神经网络是一个自下而上的思路:虽然逻辑推论是人类高级智能的突出表现,但人类在心智发展的最初时期仍然是通过观察世界,进行归纳推理,逐渐形成基础认知的。神经网络与这一点类似,以大量的数据为起点,逐渐演化出结论。这里的大量数据,实际就是关于真实世界的样例。此外,神经网络本身也是对人脑神经元的一种比较粗糙的模拟。从这个角度看,非常符合人们对创造智能的直觉。
虽然人工智能从近几年开始引爆,但神经网络的概念早在1943年就被提出了。1957年,康奈尔大学的Frank Rosenblatt第一次用算法精确定义出了神经网络,并在一年后建成了第一个基于神经网络的机器人Perceptron。后者的基础其实就是单层的神经网络。
那个年代里,占主流的是上面提到的自上而下的逻辑推理思路,神经网络方法一直受到排挤。60年代末,AI的先驱MarvinMinsky出版了《Perceptrons》一书,表达了对神经网络的质疑,其中最重要的理由就是:神经网络要求的庞大计算量在那个年代几乎不可能实现。
这本书几乎让神经网络的发展几乎彻底停止,而且一停就是10多年。直到1986年,GeoffreyHinton第一次成功用反向传播算法(Backpropagation)训练了多层神经网络。随后1988年,身在贝尔实验室的YannLeCun使用卷积神经网络,在图片识别问题上有了突破。最突出的一项运用就是用机器读取手写支票和信封上的邮编。
It was very difficult at that time(1983)actually to publish apaper if you mentioned the word‘neurons’ or ‘neuralnets.’
—YannLeCun(杨乐村儿),DirectorofAI@Facebook
这些理论突破引发了一波对神经网络的热情。反向传播算法迅速成为了非常主流的东西,一直用到现在。但那时候神经网络并没有被大规模用在工业界。由于优化过程中的效果不佳以及一些过度拟合(overfitting)问题,神经网络在图像和语音识别上的表现远不及同时期Support Vector Machine技术。后者得到了学术界的认可。
到了1990年代和21世纪初,神经网络在学术界已经不仅仅是被忽视,而是被鄙视的了。一篇带有神经网络字样的论文送到相关的学术期刊,多半很快会被直接拒绝掉。值得注意的是,这个阶段的学术界的注意力都在算法的革新上,而不是今天深度学习技术中的数据和计算能力。这可以理解,那时候随便训练一个神经系统动辄就要花几周时间,再扩大数据量还怎么玩?
神经网络突围
所幸这时候行业内的另一个玩家站了出来。1999年,Nvidia第一次提出并在随后成功普及了GPU的概念。GPU的核心目的是处理电脑游戏中同时出现的大量像素点。换言之,GPU适用于大规模的并行计算。神经网络的计算主要是有许多大量的矩阵运算组成,正是GPU所擅长的并行计算问题。我觉得完全可以这么说:游戏玩家们为人工智能的进步做出了资金上和技术上的重大贡献。(Thank you,gamers!)
2007年Nvidia推出GPU软件接口CUDA,开启了GPU在AI领域的广泛应用。吴恩达(AndrewNg)在2009年的一篇论文指出,使用GPU的运算速度是传统双核CPU的70倍。
2012年,Geoffrey Hinton带着两个学生以非常夸张的优势获得基于ImageNet的图像识别竞赛ILSVRC的第一。他们首次将深度学习的新技术用在ImageNet上,识别错误率只有15.3%。
从这时起,虽然尚未进入大众视野,深度学习已经在行业内部掀起了风暴。
2015年底,来自微软亚洲研究院的团队使用深度残差网络(Deep Residual Learning),在大幅降低计算量的前提下,将ImageNet图像识别的错误率降到了3.57%,这已经低于了正常人的错误率5%。
另一个里程碑式的事件是2012年吴恩达与学生联合发表的实验。他们用1000万个YouTube视频训练了一个9层的深度神经网络,这个网络的参数(weights)数量达到了10亿。这个神经网络后来在没有人工干预的情况下自发识别出了大量物体,其中最多的是猫。后来许多人把这个试验戏称为「CatExperiment」。
其他的几个重要突破
1997年,Jürgen Schmidhuber提出了长短期记忆模型(LSTM,LongShort-TermMemory)。LSTM作为循环神经网络(Recurrent Neural Networks)的一种,被广泛用在处理序列数据的问题上,例如语音识别。
2015年底,当时还在百度的Dario Amodei宣布他们的语音识别模型的错误率已经降低到了3.1%,低于正常人的5%。
可能最具标志性,也最为大众所知的就是今年Alpha Go战胜李世石的事情了。AlphaGo所做的就是把不同的工具和算法组合起来,结合了深度学习网络,增强学习(Reinforcement Learning)和Monte Carlo TreeSearch,起到了非常好的效果。
AI技术常识
于是,这两年看AI领域的投资人很容易会发现AI领域的两个不相容的问题:一边是AI的快速进步,更好的实用效果和更广泛的应用,以及投资人对AI的追逐。另一边是理解AI技术的高门槛和它的快速变化。
这两方带来了非常麻烦的问题。深刻理解AI技术并不确保能推演出AI在商业策略上的价值,而享受AI带来的便利和惊喜,比如Siri和AmazonEcho,也真的不需要理解什么是CNN(卷积神经网络),就像大部分互联网用户即使不知道TCP/IP为何物也不妨碍上网一样。
但如果想在AI寻找机会和创造价值,就必须得明白自己正在说的是什么。AI在技术层面是一个快速变化的东西。成熟互联网的基础设施化和中性化使得投资人可以把技术视为电力一般的事物,从而让商业逻辑和策略的推演成为可能。但AI几乎每一年都在变化。现在我们看到的许多成就都是近几年才刚刚出现的。
所以,必须一定程度上理解AI的技术本身,而不是把它视为和互联网一样的万能钥匙。
AI will transform many industries.But it’s not magic.
—吴恩达,2016.11.9,HBR
来源:Nvidia
什么是AI?
AI作为计算机,应用数学和统计学的交叉部分,其实只是一种技术手段。
可以说AI已经是现实中的一部分。Google的搜索排序,Airbnb的租房推荐价格,iPhone照片的自动分类,Pinterest的图片搜索,都是AI技术在我们日常生活中的直接体现。对于今天的我们来说,大部分软件,大部分系统,都有AI成分在里面。
另一方面,AI是一个非常宽泛的名称,它包含了所有相关的技术:机器学习,搜索与最优化,Constraint Satisfaction,逻辑推理,Probabilistic Reasoning,控制论等等。其中第一项机器学习,才包括了我们今天经常遇到的概念:深度学习(Deep Learning),人工神经网络(ArtificialNeuralNetwork),回归,决策树,SVM,PCA,贝叶斯网络,增强学习(Reinforcement Learning)等让人头大的东西。而在这之中,人工神经网络正是深度学习的根基。
什么叫神经网络?
神经网络不容易被文字定义,可以把它理解成一种对大脑处理信息方式的模仿。与大脑神经元类似,神经网络的基本单位是节点;与大脑神经元之间用来传递信号的突触(synapse)类似,神经网络的节点之间信息传递的方式用权重(weights)表示,权重也是一个人工神经网络的主要参数。
神经网络有一个非常核心的特点:联合表达(Joint Representation)。意思是说当我们用神经网络趣表达一个概念时,不是用「一个神经元存储一个定义」这样的一对一形式,而是让多个神经元,甚至整个网络共同表达一个定义。
什么叫深度学习?
「深度」最浅层的意思是:这是一个由许多层组成的神经网络。往深了说就有非常琐碎的特性,但其中重要的一点是:由于深度神经网络的多层次特性,它可以把一些认知上的抽象概念进行层次化的表达,这一点下面会说明。而所谓深度学习,指的就是训练这么一个多层神经网络,让它有能力对世界做一些判断。
什么叫(有监督地)训练一个神经网络?
所谓训练,是训练一个神经网络中各个节点的权重(weights)。可以把权重简单理解成某个输入信息的强度。
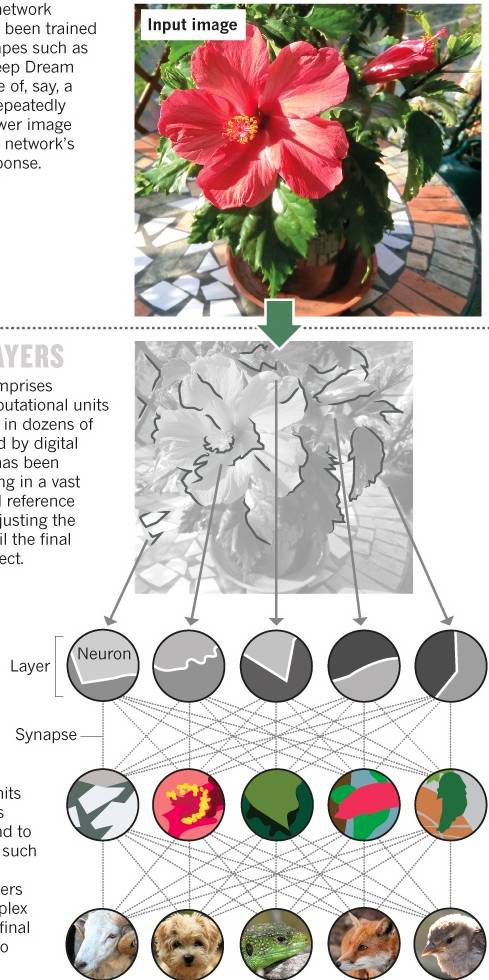
例如,我们想训练一个深度神经网络在照片中识别出猫。首先我们得有一堆人工标注过的图片,这些标注只有一个信息:图片里的是不是猫。
先把图片的像素喂给神经网络的第一层,同时对每一个节点分配一个权重。这时候第一层的节点可能会寻找图片中物体的分界线,例如不同颜色之间或者明暗分别处。随后这一层把信息传递给第二层。
第二层可能会分辨这些分界线形成的轮廓,例如形成的锐角等。
再往上的各个层级可能会寻找更加复杂的模式,例如轮廓形成的各种形状,甚至一些具体属性,例如眼睛和鼻子。
每一层都把信息向上一层传递。直到最后一层吸收下层的所有关于模式的信息,输出一个结果:这应该是只猫。
这时候每一个节点都有一个特定的权重。把这个结果和图片的标注做对比。如果与标注不一致,说明神经网络的答案错误。这时候把这个错误信息沿着神经网络反向传递回去(Backpropagate),每一层的神经网络必须对识别出的东西重新做判断。这个过程会不断重复,节点的权重也会不断发生变化,直到最上一层的输出与图片的标注相符。
所谓的学习和训练,正是这种不断地反向传播和参数修正。
上面提到,深度学习最重要的特性就是多层次的表达。在这个训练过程中,可以清楚看到,越往上的层级,识别出的东西就越抽象和复杂。
来源:Nature
什么叫做监督学习和无监督学习?
什么是监督学习(Supervised Learning)?简单地说,如果在训练一个神经网络时使用的是经过人工标注好的信息,例如上面说的,给一张猫的图片标记了一个类别「猫」。这样神经网络通过与标注的比对不断修正自己的模型,进而达到学习的目的。目前大部分已投入商用的深度学习技术主要使用的就是这种办法。
但无监督学习(Unsupervised learning)是大家更加感兴趣东西。它希望做到的是不用让人类为计算机标注数据,而是让计算机在大量数据中自己找到模式,生成对世界的认知。上面说到的2012年Google的神经网络就是在无监督的情况下识别出了「猫」这一类别。
两种方式的核心都是:数据和算法。
AI的真实现状
只有在了解了AI的历史和技术常识后,才能理解为什么突然之间AI有这么快速的发展。这点我们在之前的文章中也提过,主要有三个原因。
计算能力提升:摩尔定律,GPU的性能提升和普及,大规模并行计算的实现。
数据的大量增长:巨量数据产生源自互联网、移动设备的普及,各种设备的传感器,以及物理世界的数字化,包括图书,声音,视频,医学法律档案等等。
算法的革新。
这三个环节可能发挥了几乎同等重要的作用。然而如果从整个AI的发展历程看,前两点才是这几年AI技术的核心特征。那么谁在这两点最具备优势?显然,答案是巨头们。
从2012年起,硅谷科技巨头开始布局AI。Google最早开始行动,2012年底招募了Geoffrey Hinton的团队,李飞飞女士也在上个月加盟。YannLe Cun与2013年底开始带领Facebook的AI团队,吴恩达则在2014年成为百度的首席科学家。
剧烈变动的不仅仅是专家和大牛们的头衔。AI的快速发展进一步推动了早已在科技行业成为主流的两大趋势:开源和云端化。
开源对巨头的好处显而易见,不仅能云集所有人的智慧,提前锁定出色的工程师,还能够在行业的早期成为技术标准的确立者。对普通人来说,开源则意味着你可以免费接触到AI的开发工具和社区。现在,Google的开源AI框架Tensor Flow在Github上的星标数已经高居第二。
另一方面,云计算时代的三大厂Amazon,微软和Google先后发布了AI和深度学习的云端产品。基础的AI服务,例如语音识别、图像识别、翻译、文本识别等,都非常适合部署云端,成为标准化的产品。这个思路与云计算本身的特性,以及Twilio和Stripe对通信和支付在云端的标准化是一致的。所以对三大厂来说,在AI的世界里提供基础设施是最自然不过的选择。

AIasa Service,来源:CICC
应对AI的正确姿势
如何在AI的时代生存?
一秒钟任务
按照吴恩达博士的说法,目前AI技术中进步最快的部分其实集中在某一类问题上:输入一些数据A,然后AI给出一个简单的结论B。
这个A到B的过程,反应在现实中是什么样的任务?经验上说,如果一项脑力任务是一个人只需要花不到一秒钟就能完成的,那么现在的AI技术就很有可能会替代它。

可以说现在最流行的,进展最大的AI的技术将会出现在每一个app中。这些技术主要就是上面说到的「1秒钟领域」。实际上很多工作都属于这一类。这听起来好像不太符合直觉,但仔细一想好像确实是这样。在监控视频中识别出嫌疑行为,确定汽车会不会蹭上旁边的车辆,识别出某一种物品,都属于这一类的任务。
在目前的AI技术下,最重要的是要考虑到AI怎么样才能与自己的商业策略结合的更好。换句话说,需要在自己的整个业务流程中找到上述这样的A到B的任务,并且能找到与这个任务相关联的大量数据。
AI First的真正含义
Google在最近的发布会上宣布要变成AIFirst的公司。但AIFirst的含义是什么?
上面说到的神经网络的历史中,哪怕是在聪明人云集的学术圈,几十年来大部分人都不看好神经网络的前景。AI行业的翻转正说明了世界的复杂性和偶然性,也说明是不易被预测的。
正是这种复杂性让我相信,与我们正身处其中的MobileFirst不同,AI技术的快速变化使得对其短期未来的预测都是不可靠的。此外,深度学习领域中,实践成果已经走到的理论的前面,很多新的突破来自于借助庞大计算能力的不断尝试。因此,新的东西不断出现,许多所谓的行业积累也有可能会被迅速取代。
在这个不确定世界中,我们要从AI的价值链条中找到一些相对确定的东西。
AI的价值链条主要有三部分:算法(技术),计算能力,数据。考虑到巨头的快速反应,已经上面提到在云端AIaaS的推动,目前几乎可以肯定,AI底层的算法和计算能力最终将会是无差异的。对大部分人来说,这两部分会被抽象出来,成为基础设施,成为一个界面或者说API。
以往大家都认为只有巨头才有发展AI的机会,因为他们有人才,有数据,有大量硬件资源保证的计算能力。现在,开源框架快速发展,AI基础基础和计算能力持续云端化,加上算法的不断进步,包括小样本学习的技术,所有垂直行业的公司,包括医疗,合成生物学,金融,零售,能源,农业等,或者说理论上所有需要模式和信号识别以及最优化的领域,都有属于自己的机会。
对投资人和创业者来说,在弄明白AI的基本常识后,更重要的还是价值链条剩余的部分:数据、垂直领域的算法,以及对垂直行业的深刻理解。如何在细分行业中获得垄断级别的数据?如何在垂直领域(例如癌症检测)找到最适合的算法?如何制定相应的商业策略?
AI的终极形态
最后说一点玄乎的东西。我们一直能在新闻中看到ElonMusk、BillGates、StephenHawking等大牛对超级人工智能的担忧。对此大部分AI从业人员是不以为然的。吴恩达博士说过:
The reason I say that I don’t worry about AI turning evil is the same reason I don’t worry about over population on Mars.
吴恩达博士的意思应该是不希望对超级AI的恐惧耽误了对AI的投入,这当然是理智的观点。我认为长期来看,人类还是需要正视AI可能带来的威胁。这种威胁可能会在AI为人类带来大规模的自动化以及帮助人类提升自身智能这一段蜜月期后,才会出现。
但我看到的AI的未来形态并不是「西部世界」、「BladeRunner」或者「ExMachina」里面这样的人造人,他们模糊了人与机器边界,有自己的情感和自我意识,逼迫人类去询问一些关于自身的终极问题。
我认为AI的未来看起来不应该是人类的模样。相反,他们的外形应该与人类相去甚远。他们不需要一个实体,而是存在于机房的服务器中。也许看起来就像「2001太空漫游」的HAL9000。

HAL9000
AI作为一种智能也不需要所谓的有情感(Sentient)。人本身的情感机制即使存在,也是不容易被轻松定义的。所以AI为什么要有情感?顺着这个思路考虑下去,我们就会问出一些匪夷所思的问题出来:生活在服务器中是什么样一种体验?404页面会疼么?机器人会梦到机器羊么?
AI只想要执行我们给它的目标函数。做到了目标函数,那就是好AI,高智能。如果一个AI在这个过程中毁灭了人类,我们不能认为AI在情感上希望毁灭人类,我们要想的是:目标函数到底出了什么问题?
借用Eliezer Yudkowsky的话:
The AI does not hate you,nor does it love you,but you are made out of atoms which it can use for something else.
2012年的Google Brain实验中,使用的神经网络的参数高达10亿个。而人类大脑皮层有接近150万亿个神经元突触。看起来似乎很遥远,但要考虑到,计算能力是以10年千倍的速度在提升。按照这个速度,达到150万亿这个量级,只需要20年左右。到了那个时候,人工神经网络应该能做到一些现在的我们意想不到的事情。
(文章来源:百度百家)
第三十六届CIO班招生
国际CIO认证培训
首席数据官(CDO)认证培训
责编:houlimin
免责声明:本网站(http://www.ciotimes.com/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等)版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。




