“声纹”作为一种典型的行为特征,相比其他生理特征在远程身份认证中具有先天的优势,文章介绍了声密保在远程身份认证中的应用,解析了一些在声纹识别准确率、时变问题和噪音问题等方面的技术难点和工程解决经验,最后针对远程身份认证的安全性问题,分享了得意音通在防录音闯入上的最新研究成果。希望对广大读者有所帮助。
声纹在远程身份认证中的应用
网络安全面临重大挑战
无线互联网以及智能手机的迅速发展,给人们日常生活带来极大便利的同时也带来了不容忽视的安全隐患,如何准确、迅速、安全地实现远程身份认证成为摆在人们面前急需解决的问题。人们在实践中发现,生物特征具有唯一且在一定时间内较稳定不变的特性,这种独特的优势使得生物特征识别技术被认为是终极的身份认证技术。
生理特征和行为特征
生物特征可分为生理特征和行为特征两类,现在人们熟知的基本都是生理特征,包括指纹、人脸、掌纹、虹膜、DNA等,这些特征的特点是具有稳定性和持续的唯一性,因此基于这些特征建立的身份验证系统识别率高,但存在容易丢失和被复制的问题。相比于生理特征,行为特征也具有唯一性,但是其复制成本极高,由于行为特征具有变化性,不慎丢失后或被窃取后,也难以直接使用来闯入系统。声纹就是一种典型的行为特征。
声纹——更好的远程身份认证方式
基于生物特征的远程身份认证的一个巨大挑战是终端和网络的安全性很难被保证,若黑客从网络或终端上获取用户的生物特征,则可以轻易地侵入系统。基于声纹行为特征的特点,若系统能确认每次进入系统的声纹数据的实时性,则可以解决此问题,因为丢失的行为数据(录音)并不能通过系统的实时性检测。我们的声密保系统即这方面解决方案的一个例子。图1为声密保系统的处理流程图,声密保系统通过对动态密码语音中的密码内容及请求人身份的双重识别,实现对操作人身份合法性的双重验证。当需要认证时,系统会随机产生一组动态码(如6位或8位数字)要求用户朗读,系统对用户读出的声音进行语音识别并将识别的内容与发出的动态码数字进行比对,同时系统对用户的发音进行声纹比对,两种认证手段都通过时才判断通过。这种随机性的引入使得文本相关识别中每一次采到的声纹都有内容时序上的差异。
图1 声密保系统的处理流程图
声纹识别的一些工程经验
形简意丰的语音信号
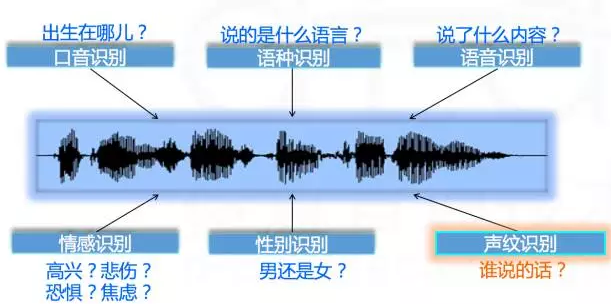
语音信号具有得天独厚的优势,形简意丰。语音表现形态简单,仅表现为一维信号,但所涵盖的信息非常丰富。如图2所示,语音信号包含语义内容信息,语种(语言、方言)信息,说话人身份(唯一身份证明)、性别信息,情感信息(高兴、悲伤、恐惧、焦虑……)等等。声纹结合内容和情感等信息是阻止声纹假冒和人身胁迫的最佳武器。
图2 形简意丰的语音信号
语音信号这一特点,使其具有极强的安全性,但同时给精确的声纹识别也带来挑战,因为很难从语音中提取纯粹的声纹特征。我们在这些方面进行了大量的算法和工程方面的工作,并取得了不错的效果。
识别准确率
虽然现在已经有许多成熟的算法使声纹识别的准确率得到了明显的提高,但相对于其它的生理特征,声纹识别仍需要做更多的工作才能达到相同的水准。
我们使用了十万人级别的数据库对系统进行训练,相比小数量级的系统,性能提升十分明显,在万人的测试数据库上,EER仍可以保持在1%以下。
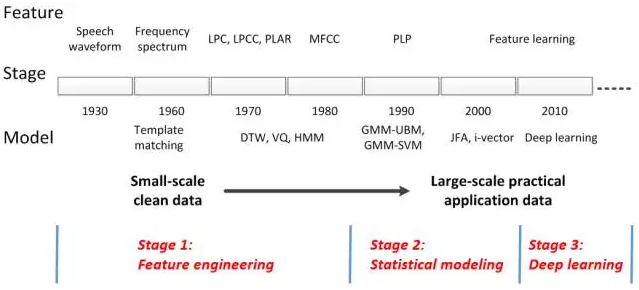
图3总结了声纹识别发展的历史以及对应的三个重要阶段。图中所展示的各类声纹识别技术我们均有深入研究,并且针对不同的应用场景我们合理的实现了“新老”技术的结合。
图3 声纹识别发展史
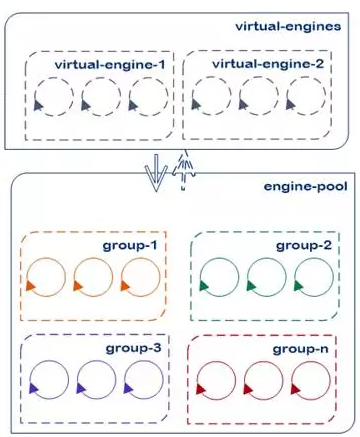
基于不同的算法,我们提出了虚拟引擎的概念,专门用于将各种算法进行融合。这种融合可以有效提高系统的识别性能,例如我们使用基于GMM-UBM和DNN-iVector的两个引擎相同的数据集上进行测试,其错误重合率仅有20%左右。图4表现了这一概念的实现,实际的引擎根据算法和配置的不同分为group、virtual-engine(虚拟引擎),调用这些实际引擎提供的接口并对算法进行融合处理,上层只需要和标准的虚拟引擎接口通讯即可。
图4 虚拟引擎
时变问题
人的整个发声系统随着时间的推移会产生一定的变化,这些变化直接导致了其语音信息中的声纹信息的变化,如果算法或系统不考虑这些变化,那么一段时间后,系统的识别性能将有所下降。为此我们录制了长达4年的100人的时变语音库,基于此语音库分析,我们找到了和时变相关的一些特征信息和规律,并试用其对MFCC和PLP特征的提取过程进行了修改。另外在工程方面,以声密保系为例,其在架构设计中就考虑到了模型的在线更新问题,并设计了专门的语音筛选算法,系统会定期的挑选用户符合条件的最新语音进行模型的重新训练。
噪音问题
正如软件工程中所提的没有银弹的概念一样,任何技术都有一定的局限性,不可能无限制地应用于任何场景,声纹技术在大噪音环境下并不适用。针对此我们开发了一套语音质量检测的库来对环境噪音和语音的信噪比进行检测,将不符合条件的语音排除在系统之外并对用户进行提示。此套噪音检测系统采用了传统的基于能量、包络、自相关系数等特征的检测算法和RNN/LSTM相结合方法,能准确的检测出96%以上不符合条件的场景。
防录音重放攻击措施
在解决这些传统问题的同时,为了保证用声纹进行远程身份认证的安全性,我们还提出了一系列防攻击措施,包括动态密码语音、用户自定义密码、多特征活体检测和录音重放等。由于篇幅有限,下面详细介绍我们在录音重放上的工作。
录音重放是一种常见的声纹特征盗取手段,由于采用动态密码的方式,很难将一个人的各种发音组合全部录制下来。但我们还是假设如果把这个人所有的文本发音(在声密保系统中为0~9的数字发音)全部录下来,然后根据系统提示的数字密码进行拼接重放,那么还是同一个人的声音,是否能够通过声纹识别系统验证呢?
我们先分析一个典型的录音重放过程:
正常语音信号:y(t)=x(t)*a(t)
录音重放语音信号:y’(t)=x(t)*a’(t) *d’(t)*a(t)
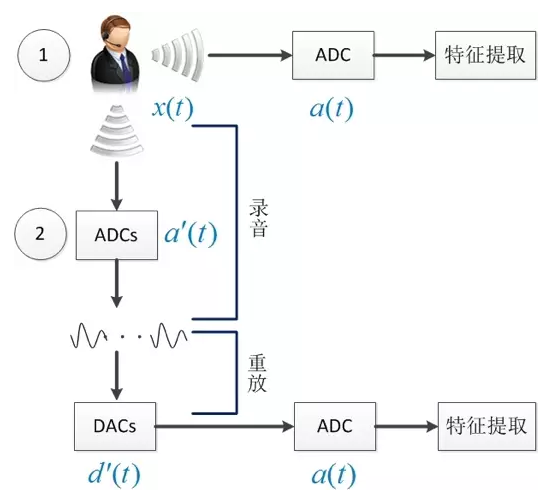
图5中录音ADCs(模数转换)和重放DACs(数模转换)是对语音信号的两次传输,均会对原始信号产生影响,且ADCs和DACs是非连续可逆的,除了ADCs和DACs外,传输过程还包括噪音、混响等因素,录音重放会造成信道失配和信号强度衰减等现象。
图5 典型的录音重放过程
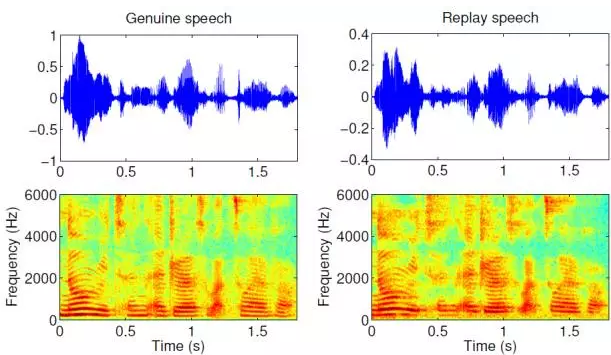
图6给出了一段真实语音和其录音重放后语音的时频分析,可以看出在这种情况下真实语音和录音重放语音很难被区分,录音重放可以说是最容易实施和最难被检测的假体攻击方式。
图6 一段真语音和录音重放语音的时频分析
2017年的Automatic Speaker Verification Spoofing and Countermeasures (ASVspoof) Challenge中,首次将录音重放检测纳入到说话人识别的防闯入比赛中,一个理想的录音重放检测系统应该在已知和未知的条件下都很鲁棒,包含与训练数据不同的说话人、不同的录音重放内容和不同的录音重放设备。ASVspoof针对录音重放检测进行的比赛中,全球近100个团队参加,最终提交了49个,我司的结果排在第5。相关的声纹确认防录音论文发表在Interspeech上。
《A Study on Replay Attack and Anti-Spoofing for Automatic Speaker Verification》论文主要分两部分:第一部分分析了不同的说话人、文本和设备对录音重放检测性能的影响;第二部分给出了有效的录音重放检测算法实现。
论文用F-ratio来分析不同因素对重放检测性能的影响。F-ratio是一个简单的频域加权方法,频带的权重可以由其对任务的判别能力决定。假设在分析语音谱时采用的滤波器个数为M,第i个滤波器的F-ratio可以定义为:
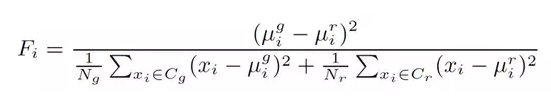
Cg表示真实语音,Cr表示重放语音。xi表示第i个滤波器语音帧x的值,和分别是滤波器内真实语音和重放语音所有帧的均值,Ng和Nr分别是两类语音的语音帧数。最后用M个滤波器的F-ratio值组[F1,F2,…,FM]来分析真实语音和重放语音在不同频带上的区分性。
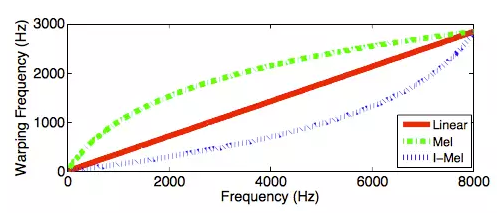
在ASVspoof中,开发集和测试集中含有比训练集种类更多的录音重放设备。在训练集中利用少量设备的录音重放语音进行模型训练非常容易导致过拟合,弱化了提取的特征和训练的模型的概化能力。为了提高概化能力,降低这种变化对重放检测的影响,论文采用了频率弯折的方法,如图7所示,Mel方法增强了特征在低频段的区分能力,IMel方法增强了特征在高频段的区分能力。
图7 三种频率弯折曲线
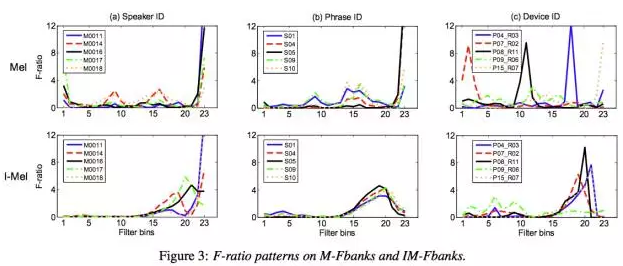
图8给出了在Mel和IMel两种频率弯折方法下,不同的说话人、文本内容、和录音重放设备在滤波器组上的F-ratio值,从(c)列图中可以看出用Mel方法,不同的录音重放设备对滤波器组的F-ratio值影响很明显;但是IMel方法大大降低了设备间差异对F-ratio的影响,这对后面建立概化能力更强的模型具有非常重要的意义。
图8 Mel和IMel方法在不同的说话人、文本和设备情况下对F-ratio的影响
在录音重放检测部分,论文使用(MFCC,LPCC和IMFCC)三种特征在训练集上建立了基于GMM、ivector/SVM和DNN的重放检测系统,并在开发集中进行了测试。从下面结果可以看出IMFCC特征是最有效的,最简单的GMM模型取得了最好的效果,DNN模型虽然在表中也取得了不错的效果,但是存在不稳定的问题,不同的初始化将导致不同的结果,有的差异很大。
其实在日常生活中用手机进行录音重放是最方便的。相比于多样性的录音重放设备,手机等移动设备上的录音重放检测要简单的多,我们曾经对60种不同型号的手机进行了接近十万条的录音重放检测,结果重放的检出率基本为100%。
总结
声纹作为生物特征中的行为特征,配合语音识别技术,通过互动方式在远程身份认证“用自己来证明自己”方面有其他生物特征难以替代的优势。当然,就像前面提到的任何技术都有一定的局限性,不可能无限制的应用于任何场景。只有通过结合声纹和其他生物特征组成多因子认证手段,才能更好地保证远程身份认证安全。
第三十八届CIO班招生
国际CIO认证培训
首席数据官(CDO)认证培训
责编:houlimin
免责声明:本网站(http://www.ciotimes.com/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等)版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。