2013-11-27 11:07:23 来源:w-works
随着各行各业信息化的要求越来越高,需要存储的数据量越来越庞大,然而,已经存储的数据中有相当一部分是重复的,这样既浪费存储空间又增加了存储的工作量。为了缓解存储系统的空间增长问题,重复数据删除技术已成为一个热门的研究课题。
云存储技术以提供数据存储服务来解决存储设备管理维护、安全稳定和成本问题,实现存储设备向存储服务的转变。重复数据删除技术旨在消除数据大量冗余,缩减存储空间。两种技术的结合,充分将两种技术的优势发挥得淋漓尽致,既能将海量数据存储在云端,又能充分利用云端的存储资源。两者结合有很大的应用价值。
本文通过研究重复数据删除和云存储,提出了一个基于云存储的重复数据删除架构, 使得海量数据能够存储在云中并且拥有重复数据删除的能力。它采用In-line方式对文件进行数据块级与字节级相结合的重复数据删除,使用MD5算法计算数据块的哈希值并与已存在的数据哈希值对比来判断上传的数据是否存在于云中。
1.云存储简介
云存储是在云计算(cloud computing)概念上延伸和发展出来的一个新的概念,是指通过集群应用、网格技术和分布式文件系统等功能将网络中大量各种不同类型的存储设备通过应用软件集合起来协同工作,共同对外提供数据存储和业务访问功能的一个系统。
1.1 云存储结构模型
云存储是一个网络设备、存储设备、服务器、应用软件、公用访问接口、接入网、和客户端程序等多个部分组成的复杂系统。各部分以存储设备为核心,通过应用软件来对外提供数据存储和业务访问服务。现有的云存储结构模型如图1所示。

图1 云存储结构模型图
1.2 云存储与重复数据删除
云存储是将使用了弹性配置和按需付费的因特网技术的可扩展、弹性的存储能力作为一种服务在服务提供商和用户之间传输。因为云存储提供了完整和安全的访问控制机制, 所以大部分用户都愿意将数据存储任务交予云存储。
重复数据删除是高性能和高效存储的一种有效途径,尤其是在云计算环境下使用。这是因为服务的存储空间可能成为成本负担,利用存储效率技术(如重复数据删除)的能力逐渐成为判断服务是否合格的一个关键指标。
2.重复数据删除技术分析
2.1 重复数据删除策略分析
目前重复数据策略主要分为三种: 文件级的重复数据删除,数据块级的重复数据删除和字节级的重复数据删除。它们根据检测删除重复数据的单位不同而不同。通过研究和比较发现,文件级删除策略虽然计算速度快,但粒度太粗无法精确识别重复数据。数据块级删除策略较精确,但因为以数据块为单位故需计算的哈希值较多,且可能产生哈希冲突。字节级删除策略以字节为单位进行对比不涉及哈希算法,所以可以避免碰撞,能够实现更高的精度,但是花费的时间太多。
为了保证重复数据删除的精确性和计算时间相对平衡,本架构选择了数据块级与字节级策略相结合的重复数据删除策略。先将文件分割成数据块,以数据块为单位计算其哈希值。如果新数据块的哈希值与设备散列索引中的某个散列匹配时,将新数据块与已有的与它哈希值相同的数据块进行字节级的对比,若完全相同时仅存入指针并指向存储相同数据块的原始位置,否则,如果数据块是唯一的,就被写入磁盘,其哈希值也存入索引中。这种方法的优点是有效的使用数据块级策略的优势又能利用字节级策略避免哈希冲突时带来的数据丢失。
2.2 重复数据删除算法分析
现有的重复数据删除算法大致分为两类,分别是hash 算法和基于内容识别的算法,与其对应的是文件级或数据块级的删除策略和字节级策略。
Hash 算法的数学表述为: CA=Hc(content)。其中content表示任意长度字符串,CA 表示经过哈希变化之后得到的哈希值。Hash 算法在信息安全领域中广泛应用,现在最常用的哈希算法是MD5和SHA-1 算法。本架构采用的是MD5 算法。
2.3 重复数据删除实现方式分析
重复数据删除主要有两种实现方式—前台处理方式和后台处理方式。前台采用纯软件的方式进行,而后台采用软硬件相结合的方式,其中又分为In-lineDeduplication 、Post-Processing Deduplication 以及Adaptative Data Deduplication 三种。
通过研究比较发现In-line 方式更适合云存储系统。数据传输之前,装有重复数据删除应用程序的客户端先对其进行操作之后再传给数据节点存储处理。它在数据块写入前检测是否已有相似数据块存在,这样可以避免磁盘数据写入,提高云存储系统的空间存储效率并减少网络传输。
2.4 小结
本架构采用了数据块级与字节级相结合的删除策略,运用MD5 算法对要存储在云中的文件进行In-line方式的删除操作,是本文研究的一个创新点。较之现有的在云存储中使用文件级或数据块级策略的操作,精确性上有所提高;较之使用Post-processing 方式的删除有时间和空间上的优势。另外,在云存储上使用该方法,结合云的虚拟化和分布式计算存储的特性很好的解决了In-line 方式使主机I/O 负载过大的问题。
[page] 3.基于云存储的重复数据删除架构
基于云存储的重复数据删除架构由两部分组成,由于使用的是In-line 方式进行重复数据删除,则第一部分是安装了重复数据删除应用程序的客户端;另一部分是Hadoop Distribute File System 分布式文件系统和HBase数据库系统。客户端可分别与HDFS、HBase相互通信。
3.1 数据存储
在基于云存储的重复数据删除架构中进行文件存储时需要存储两类数据: 海量的原始数据和指针索引信息。
3.1.1 海量数据存储
原始数据包括源数据块和数据块链接文件。源数据块是指首次上传并存储在系统中的数据块,数据块链接文件是系统中已存在的数据块再次上传时,不再进行存储操作转而使用链接文件的形式来存储。每个链接文件都记录了它对应源数据块的哈希值和逻辑路径。
3.1.2 索引信息存储
HBase 中有一张数据表来存储索引信息。此表有四列,分别是hash_value,count, path 和source_file,记录每个数据块的哈希值,被索引值、源数据块逻辑路径和它隶属的文件名。其中hash_value 是主键。
3.2 文件存储
在基于云存储的重复数据删除架构中存储文件主要分为四步:
① 在重复数据删除客户端上用户选择要上传的文件,客户端上的重复数据删除应用程序先将文件分割成数据块,运用MD5算法来计算每个数据块的哈希值。随之传给HBase 进行记录。
② Hbase 某个数据块的hash 值,若该值不存在则将其记录,转向第3步;否则,HDFS 检查此数据块被索引值是否为0,若不为0 则count 值加1,HDFS告知客户端此数据块已经存在;若为0 则转向第3 步。count的值随被索引的次数变动而变动。
③ HDFS 存储该数据块并且将其与链接文件关联起来,同时存储它的哈希值和逻辑地址。
④ 重复2,3步的操作直至上传文件的所有数据块都存储完毕。其UML活动图如图2所示。
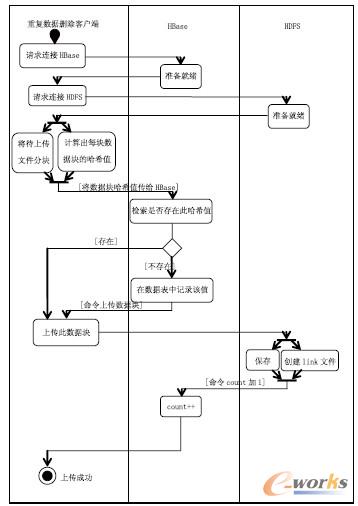
图2 云存储重复数据删除架构中文件存储的Active图
3.3 文件访问
当客户端发起访问请求时,HDFS 会找到该文件各个数据块的链接文件,链接文件将逻辑地址传递给HDFS。之后HDFS 询问主节点数据块的位置,客户端得到块地址,最后从数据节点中取回源数据块。依次访问所有数据块完毕后访问文件成功。访问文件的UML活动图如图3所示。
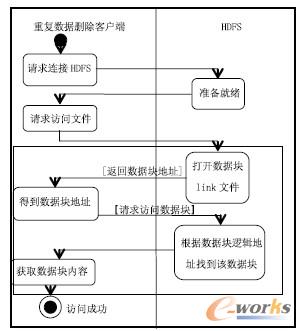
图3 云存储重复数据删除架构中文件访问的Active 图
3.4 文件删除
一个源数据块可以被多个链接文件索引,删除链接文件对数据块毫无影响。当删除指向的最后一个链接文件后,即count 值为0,源数据块的存在也没有了意义,所以在此时该源文件也会被删除。系统中不同用户有权利访问相同的文件,但是不允许某个用户删除另一用户分享的源文件。链接文件可以很好的起到保护源文件不被其他用户删除的作用。删除文件主要分为三步:
① HDFS命令删除数据块的链接文件。
② HBase中count值减1。检查count 若为0 则删除该源数据块。
③ 重复1,2 直至要被删除的文件所有数据块完成删除操作。删除文件的UML 活动图如图4所示。
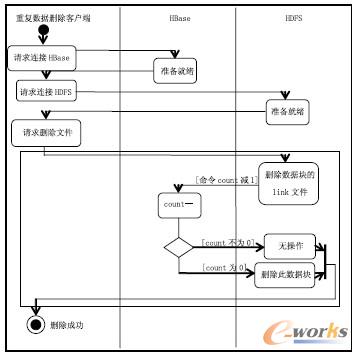
图4 云存储重复数据删除架构中文件删除的Active图
4.测试与分析
在Vmware7.10workstation 上搭建起了的云存储平台。平台中有1 台主机和4台虚拟机使用的主机的配置如下:CPU 为3.0GHZ,内存4G,硬盘320G。四台虚拟机的配置一样,CPU2.8GHz,内存512Mb,内存120G。实验上传了1000 个文件,共占19.8Gb。在一个普通的存储系统中,这1000 个文件肯定会占19.8Gb 的容量;在本架构中,存储在云中的文件只占6.93Gb。在容量上确实有节省空间的效果。
5.结语
本文通过利用数据块的hash值作为索引存储在HBase来获取高性能的查询同时在HDFS 中使用link文件来管理海量数据来实现云环境下的重复数据删除。通过数据块级与字节级相结合的重复数据删除策略提高了数据重复删除粒度,减少了数据存储空间,并用实验证明了其删除的能力。
另外,基于云存储的重复数据删除比普通重复数据更有优势。1.重复数据删除的关键技是数据分块与数据指纹计算。虽然MD5算法的计算复杂性非常高以至于占用很多的CPU 资源,且数据指纹需要保存和检索使得索引表越来越大。但是将重复数据删除应用在云存储上即可以发挥云存储虚拟化和云计算分布式计算的优势,构建集群的重复数据删除架构,为用户提供多倍的吞吐及处理能力。2.单点故障时其他设备可自动接管其工作以保证处理的连续性。由于集群仍然保留的是单个Hash表所以它不仅提高了系统性能而且不会影响到重复数据删除比率。3.云存储融合云灾备技术可以解决软硬件损坏造成的数据损坏和丢失问题。
免责声明:本网站(http://www.ciotimes.com/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等)版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。




