2012-09-27 11:46:00 来源:CIO时代网
Hypertable支持顺序读和随机读,相比顺序读,随机读的性能并不好。由于随机读(非批量)性能较低,基于Hypertable的某些应用功能也很难实现,因此优化随机性能对支持更多应用以及提升系统整体性能都非常有好处。
如图8所示,使用IOzone对一些常见机型的机器磁盘做随机读测试,可以看到,如果访问落到磁盘,性能会非常差,最好吞吐也是小于2MB/s.
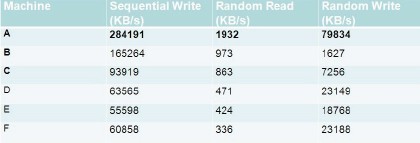
图8 各种机型磁盘随机读写吞吐对比
解决:从磁盘分级、内存模式和Cache支持三个方面进行解决。
(1)磁盘分级向Hypertable系统导入470GB的原始数据,导入后经压缩实际占用360GB×3副本≈1.1TB磁盘空间,大约分裂为2600多个Range,平均每台服务器负责近300个。以下测试进行了3轮,每轮都分别进行单进程和多进程随机查询,每个进程共完成1000次查询。相对于第一轮,第二轮进行了两项优化:对row key进行了反转,例如1234→4321,从而使之分布更均匀;调整每个range的cell store个数上限到5(默认是10),第三轮则把cell store个数进一步缩小到1(通过发命令强制做major compaction)。测试结果如图9所示。
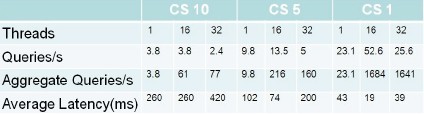
图9 cell store文件数配置不同时导入性能对比
此测试最大的特点是数据量远大于内存总数,因此存在较多随机磁盘访问。以第二轮16进程查询为例,平均每个Range有4.4个Cell Store文件,因此每秒需要进行4.4×216≈950次HDFS文件随机访问。每读一次HDFS中的文件实际至少需要访问两个文件:一个blk文件和一个meta文件,因此每秒至少需要950×2=1900次随机磁盘访问,这还不算dentry cache miss和超时重试。观察发现,实际测试过程中最繁忙的节点每秒的磁盘随机读取次数达500多次,磁盘I/O利用率达到100%.第三轮测试同样有类似的规律。因此我们可以得出结论,数据量较大时,Hypertable的瓶颈在于磁盘随机I/O次数。
我们使用分层的方式来提升磁盘随机访问性能。固化存储分级为SSD/SATA/SAS,随机读性能要求高的应用数据存储到SSD,依次类推。测试发现,使用SSD,随机读性能提升60%以上,不过随机写性能会有部分下降,而且SSD的更新寿命约为1万个操作。
(2)内存模式
对于那些频繁访问的数据,我们可以将其设置为in memory方式,这些数据将一直驻留内存(直接用一个C++ std::map结构存起来的,本质上相当于使用了红黑树索引),因此随机查询时不用从文件里读,效率很高。
如果只用一台Range Server,使用1个进程查询同一行数据(共约600字节数据),速度可达4650次/s,若用16个进程并行查询,每秒总查询次数达到12700次,40进程时达到峰值16000次/s,相当于约10MB/s;如果每次查询50行数据(40进程并行查询),每秒查询次数下降到1300左右,但聚合带宽达到40MB/s.此过程Range Server的CPU sys时间较高(30%~40%),但user和iowait时间都比较低,因此认为瓶颈在网络RPC上。
但in memory这种模式非常耗费内存,原因有以下两点。
由于Hypertable设计时为了支持稀疏表,每个value是单独存的,而不是按行存的,因此每个value都需要存一份key (包括row key、column family、column qualifier和timestamp,最小开销16字节),再加上map数据结构的开销24字节,一个value至少有40字节额外开销,一个帖子就是40×13=520字节,比帖子的实际内容(平均300多字节)还多。
为了支持高并发,Hypertable采用了MVCC(Multi-version Concurrency Control)模式存储<key, value>,也就是说,删改一个value时只是追加了一个补丁,而不是在原值基础上修改,多余的版本只有当Cell Cache大小达到一定程度时才会清理。
(3)Cache支持
当前版本的Hypertable依据当时的负载状况,动态调整分配给每个子系统的内存。对于读密集型的负载,Hypertable分配大部分内存给Block Cache;而HBase则固定分配20%的Java Heap作为Block Cache.此外,Hypertable还提供Query Cache机制,缓存查询结果,使得其随机访问性能超过了HBase,如图10所示。当然,Bloomfilter机制对HBase和Hypertable都支持,能够避免大量的无效访问。
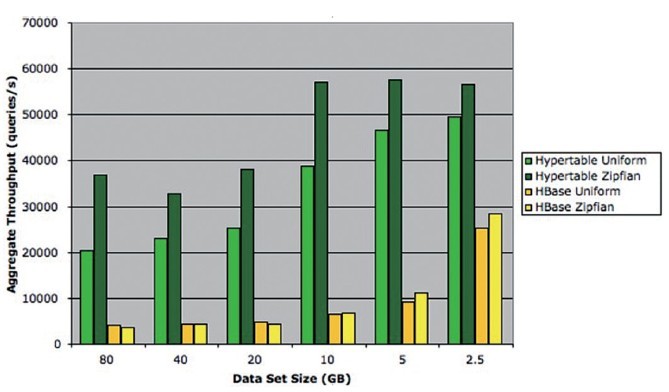
图10 Hypertable vs. HBase随机读吞吐量测试
总结:HBase在Facebook的应用非常成功,后端平台的实时改进提高了其前端的业务水平。而Hypertable尚未在业界大规模使用,但我依然非常看好它,看好其精细的架构和高质量的代码实现。相信未来将会有更多的开发者来使用和改进Hypertable系统。
Hypertable内存优化 图
Hypertable的安全停机策略
Hypertable的分裂日志策略
Hypertable集群故障处理
Hypertable高可用改进架构 图
Hypertable与HBase业务应用比对 图
免责声明:本网站(http://www.ciotimes.com/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等)版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。




