2022-05-16 17:32:12 来源:
5 月 12 日, 信服云大数据研发技术专家 Cody 在信服云《Tech Talk・云技术有话聊》系列直播课上分享了《基于低代码的数据开发》, 详细介绍了低代码平台如何提升用户的数据开发效率, 传统的数据仓库、实时计算开发、离线计算开发场景面临的挑战和解决方案, 以及信服云大数据在安全日志分析、数据仓库方面的数据开发经验等内容。以下是他分享的内容摘要, 想要了解更多可以关注“深信服科技”公众号观看直播回放。
一、Studio 架构和定位
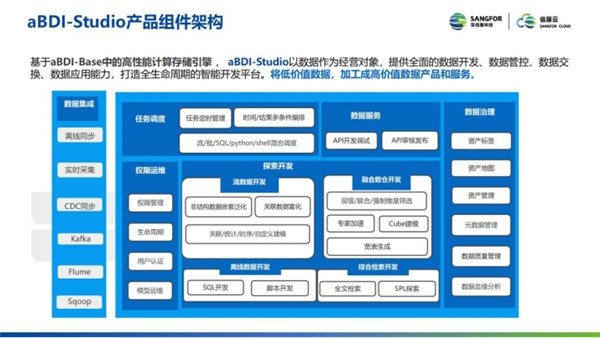
aBDI-Studio 是基于 aBDI-Base 基础平台, 以数据作为经营对象, 提供全面的数据开发、数据管控、数据交换、数据应用能力, 打造全生命周期的智能开发平台, 通过该平台, 可以将低价值数据, 加工成高价值数据产品和服务。
Studio 包括数据集成、任务调度、数据服务、数据治理、权限运维、探索开发。其中, 探索开发包括流数据的开发、融合数仓的开发、离线数据的开发、综合检索开发等四大部分。探索开发关系到平台的开发效率, 也是本次直播的重点内容。
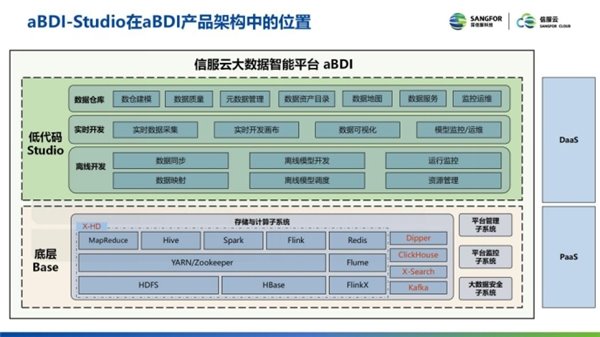
aBDI 产品包含两大部分, 一部分是底层 base 平台, 一部分是上层低代码开发平台 Studio。Studio 在 aBDI 产品架构中位于上面应用层, 其功能主要集中在数据仓库开发、实时开发、离线开发。数据仓库开发包含了数仓的建模、数仓的质量、源数据的管理、数据资产目录、数据地图和数据服务, 以及数据同步。
低代码数据开发平台跟传统的数据开发不同点在于, 传统数据开发用时较长, 中间环节较多。以业务变化为例, 它要先去做一个业务的需求变化确认, 再进行代码开发, 代码开发完之后联调, 接着是功能测试和系统部署, 最后是停机发布。这一整个流程花费时间较多, 效率也不高。
低代码的应用场景, 一部分要实现高稳定性, 满足稳态业务开发的维护需求; 同时也要保障灵活性和通用性, 可以适应敏态业务快速变化的需求。
基于低代码的开发可以简化这些步骤。针对业务变化和需求确认, 用户只需要做后面的系统配置, 联调和测试是在低代码开发平台直接覆盖。低代码开发平台可以说既高效又灵活, 不仅节省了流程需要的时间, 也不需要人力再去做任何配置。
Studio 平台的受众包含四类人群: 在数据开发或者应用过程中, 数据开发者可以编辑和调度开发能力, 拖拽任务组件、编排业务流程, 降低开发门槛, 快速上手; 对于数据资产的管理人员, 可以通过实现资产的统一管理, 平台里提供了丰富的资源管理操作功能, 包括文件的上传、下载等; 对于运维人员来说, 通过模型的运维可以进行数据语言的接入配置管理, 以及模型运行监控和异常告警, 这样可以简化运维; 对于数据分析师来说, 平台的数据探索提供了管道式的检索语言, 最终处理完的数据可以通过 spl 去查找数据, 比较自由灵活, 屏蔽了底层, 不需要感知底层那么复杂的接口, 这解决了编程式探索操作复杂的痛点。
二、Studio 数据仓库开发
传统的大数据数仓的建设, 一般都是由建模工程师提出分析用户需求, 提供数仓的建模的指标信息, 提交给开发工程师。开发工程师拿到需求之后进行编码实现, 编码完成后, 会自己去提交测试, 测试工程师会根据提交的应用去测试。测试结束, 应用即可发布。发布之后, 建模工程师就去看发布后的应用, 验证模型是否符合用户的诉求。
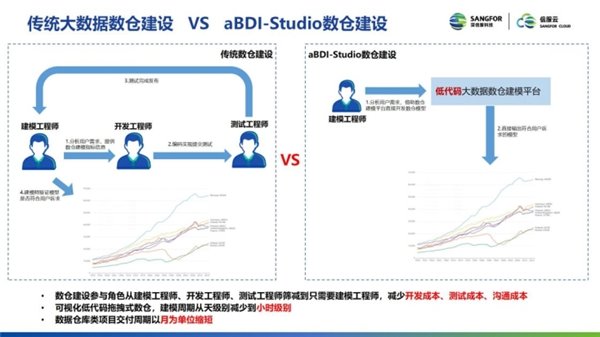
在低代码的开发平台, 步骤简化成: 数仓建模工程师会去分析用户的需求, 借助数仓的建模平台直接开发数仓模型, 低代码的大数据建模平台直接可以给建模的工程师用, 可以直接在上面调试, 也不需要写代码。模型发布之后, 可以直接看到输出的结果, 也不需要开发工程师介入, 就直接在一个平台上看到想要的结果, 也可以验证一下模型的输出是否符合用户的诉求, 以及模型跑完的结果是否正确。
对比来看, 传统的数仓建设参与角色包括建模 / 开发工程师、测试工程师等, 但 Studio 只需要一个建模工程师, 这样可以减少开发成本、测试成本、以及沟通成本。同时,Studio 支持可拖拽, 通过“拖拽”就可以把一个模型建好, 建模周期大大缩短, 由原来“天级别”到了“小时级别”。模型建完之后, 按照传统的流程需要以周期来发布, 周期可能会比较久。但是 Studio 上的数仓的建设, 刚创建好之后, 就可以直接发布, 交付周期也大大缩短。
三、Studio 实时计算开发
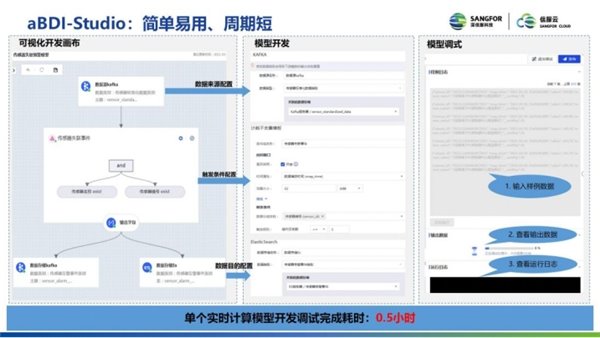
传统方式一般需要写一段代码, 以 Flink 为例, 它可能要写到 Flink 的代码。在 Flink 的代码里面, 第一部分还要定义一个数据源和一个数据目的。最后数据源和目的之间, 它会有个数据算子, 比如它要制定一个 map 算子或者是 aggregate 聚合算子或者是转换的算子, 模型开发完之后, 进行调试。调试之后要通过命令行的方式往数据源中打入样例的数据, 然后提交。最后去查看单个实时计算模型开发调试完成的耗时, 这样的开发流程单次可能需要 8 小时。
但是在 Studio 里面开发周期就比较短。首先它要拖一个数据源, 然后再拖两个数据目的, 中间是算子。而数据源只需要在界面上去配置即可, 再配置触发条件和数据目的。这些也都可以在可视化画布里面开发完之后再去配置。配置完成后还可以通过调试模型的方式调试, 查看数据对不对。
四、Studio 离线计算开发
离线计算开发步骤包括: 业务开发、资源管理、模型开发、定时管理、模型管理。
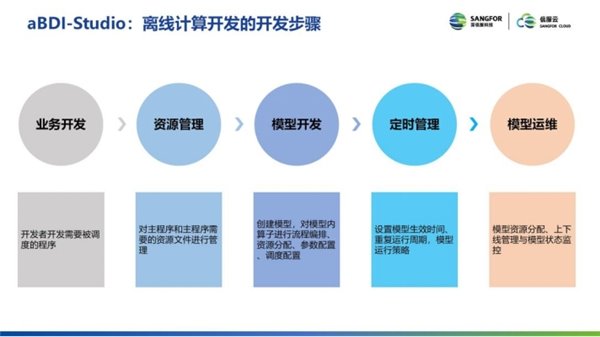
具体来说, 第一步是模型的开发。开发人员是要先把算子拖拽到画布中。第二步, 把程序和资源配置到算子中间。比如说要把 Spark 的应用或者 Flink 的应用或者一个 Python 的脚本上传, 给应用程序运行时使用。第三步, 配置一下算子之间的依赖关系。这里面的算子端就区分处理类的算子、流程类的算子。当上游的算子执行成功之后才执行下游的算子, 在模型开发中, 通过简单拖拽即可实现。
aBDI 里面的 Studio 离线开发, 底层的技术实现跟业界的方案有些不同, 主要是增强稳定性和提高易用性。
不同点体现在以下方面:
(1) Studio 支持 HA , 去中心化的多 Master 多 Worker ;
(2) 对于过载处理, 当任务过多时会缓存在队列中, 所有任务都运行在集群中, 不会造成服务器卡死;
(3) 不会影响正在运行的任务进程;
(4) 当进程宕掉的时候, 会自动会拉起;
(5) 监控界面上,DAG 监控界面支持查看任务状态、任务类型、重试次数、任务运行机器、可视化变量、运行时间、错误日志;
(6) 所有流程定义操作都是可视化的, 通过拖拽任务来绘制 DAG, 配置数据源及资源。同时对于第三方系统提供 API 方式操作;
(7) 在快速部署上, 实现可视化一键部署。
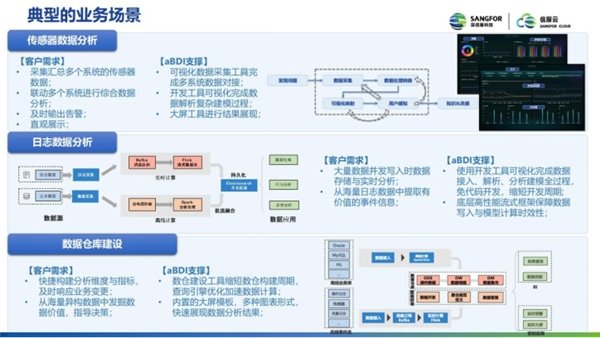
Studio 低代码平台目前主要用在如下三个场景。第一个是传感器的数据分析, 首先由用户去采集多个系统的传感器数据, 然后联动多个系统进行数据分析, 产生告警后及时输出告警直观展示。用户可以通过 Studio 去完成发现问题、数据采集、数据处理转化、可视化的映射、用户感知的流程等一整套的过程。
第二个场景是日志分析。平台通过数据源把日志采集过来, 放到消息队列之后通过流处理或者是离线的方式处理, 之后会持续写到 ES 里, 再基于 ES 的结果, 用户进行数据的检索跟行为的分析或者异常分析。Studio 也擅长帮助用户处理有大量并发写入的实时数据、数据的存储、希望能够实时分析以及从海量日志中提取有价值的数据。
最后一个场景是数仓建设, 是从数据的接入到数据的处理、再到数据模型的构建和数据的查询, 这些过程,Studio 基本上都能覆盖到。
以上就是本次直播的主要内容。对大数据低代码开发感兴趣的 IT 朋友可以关注“深信服科技”公众号回顾本期直播, 了解更多技术内容。
免责声明:本网站(http://www.ciotimes.com/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等)版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。




