2021-09-29 16:35:48 来源:
9月28日,浪潮人工智能研究院在京发布全球最大规模人工智能巨量模型 “源1.0”。“源”的单体模型参数量达2457亿,超越美国OpenAI组织研发的GPT-3,成为全球最大规模的AI巨量模型。“源1.0研讨会”同期举行,来自国内相关领域的院士、专家出席了研讨会,对AI巨量模型的创新与应用进行了深入研讨交流。
源1.0模型参数规模为2457亿,训练采用的中文数据集达5000GB,相比GPT3模型1750亿参数量和570GB训练数据集,源1.0参数规模领先40%,训练数据集规模领先近10倍。
“源1.0”在语言智能方面表现优异,获得中文语言理解评测基准CLUE榜单的零样本学习和小样本学习两类总榜冠军。在零样本学习榜单中,“源1.0”超越业界最佳成绩18.3%,在文献分类、新闻分类,商品分类、原生中文推理、成语阅读理解填空、名词代词关系6项任务中获得冠军;在小样本学习的文献分类、商品分类、文献摘要识别、名词代词关系等4项任务获得冠军。在成语阅读理解填空项目中,源1.0的表现已超越人类得分。
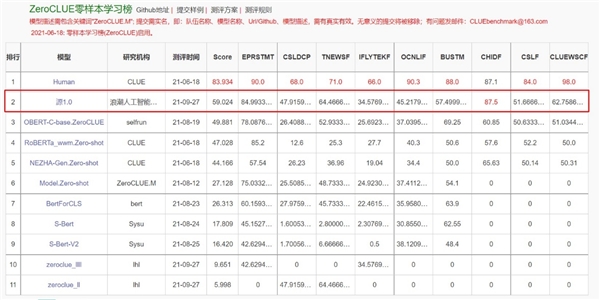
ZeroCLUE零样本学习榜(第一行为人类得分)
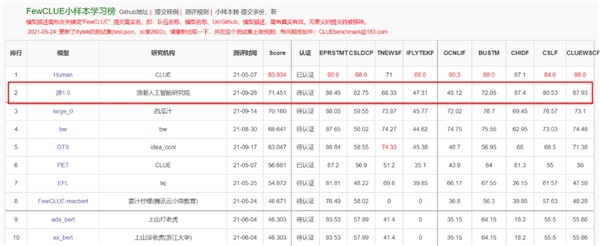
FewCLUE小样本学习榜(第一行为人类得分)
在对“源1.0”进行的“图灵测试”中,将源1.0模型生成的对话、小说续写、新闻、诗歌、对联与由人类创作的同类作品进行混合并由人群进行分辨,测试结果表明,人群能够准确分辨人与“源1.0”作品差别的成功率已低于50%。
巨量模型的发展备受关注。斯坦福大学李飞飞教授等人工智能领域知名学者近期在论文中表示,这类巨量模型的意义在于突现和均质。突现意味着通过巨大模型的隐含的知识和推纳可带来让人振奋的科学创新灵感出现;均质表示巨量模型可以为诸多应用任务泛化支持提供统一强大的算法支撑。
源1.0中文巨量模型的发布,使得中国学术界和产业界可以使用一种通用巨量语言模型的方式,大幅降低针对不同应用场景的语言模型适配难度;同时提升在小样本学习和零样本学习场景的模型泛化应用能力。
浪潮人工智能研究院表示,“源1.0”将面向学术研究单位和产业实践用户进行开源、开放、共享,降低巨量模型研究和应用的门槛,有效推进AI产业化和产业AI化的进步,切实为国家在人工智能研究创新和产业发展作出贡献。
免责声明:本网站(http://www.ciotimes.com/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等)版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。




