2019-03-26 16:41:30 来源:互联网

MS MARCO是微软发布的一套由10万个问答组成的数据集,它建立在经过匿名处理的真实世界数据基础之上。数据集中的问题来自于微软必应搜索引擎和微软小娜虚拟助手中的真实的、匿名的查询,与问题的匹配的文章来自于必应搜索引擎的真实搜索结果。每个问题给定10篇相关段落,其中一般只有1~3个段落能够真正回答问题。相比SQuAD等其他阅读理解数据集更接近真实问答场景且难度更高。
微软将这套数据集免费向广大研究人员提供,发起MS MARCO挑战赛,以推动机器阅读领域的研究,使其也能如图像和语音识别领域一样取得突破,同时促成有助于达成“通用人工智能”这一长期目标的科技进步,让机器能像人类一样思考。参赛的队伍包括,微软、三星、日本电报电话、百度、阿里巴巴、中山大学、中科院计算所等国内外知名企业、大学和研究机构。
MS MARCO在阅读理解方面分为两个子任务,Q&A任务和Q&A NLG任务。其中Q&A任务即众包工作人员根据一系列段落和问题生成该问题的答案。但Q&A任务的答案可能相对简短,甚至不完整,这时该答案会被重写,保证有正确语法的完整的自然语言描述,即更接近于人类自然语言,这便是Q&A NLG任务。
比如同样的提问,“宋小宝是东北人吗? ”Q&A任务的答案是“是”,而Q&A NLG任务的答案是“宋小宝是东北人。”,相较于Q&A任务,Q&A NLG任务更加复杂,模型也更加困难。
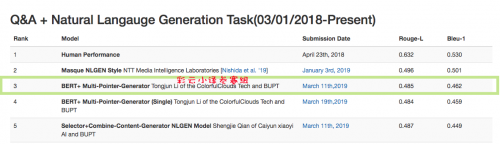
彩云小译AI背后的自然语言算法模型一直在不断训练和优化中,从去年开始,彩云小译AI团队和北京邮电大学合作致力于研究机器阅读领域,训练AI更好理解人类问题并作出接近人类语言的自然回答,并取得了突破性的进展。即使在更为复杂的Q&A NLG任务中,彩云小译也取得了不俗的成绩。
彩云科技一直在努力,致力于使机器也能像人一样学习交流并能充分了解或理解人类所说, 从而能优化用户的搜索答案,更迅速便捷地得到用户想要的信息。
想象一下,机器帮你过滤掉无用的不相关信息,搜索引擎给你的回答精准匹配你的问题,甚至,你不需要阅读完整篇文档,直接投喂资料给机器,然后对你想知道的问题答案提问,机器就可以告诉你你想知道的一切。
“让机器更懂你”。未来,彩云科技将会更加努力,使人工智能更好的服务人类社会,让人类世界因彩云科技而变得更加美好。
免责声明:本网站(http://www.ciotimes.com/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等)版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。




