近年兴起的移动直播,其富有特色的模式吸引了海量用户,已成为网络社交和粉丝经济的超级入口。在直播过程中,声音是主播与观众互动的重要途径,为了丰富直播内容、带动气氛、增加趣味性,主播普遍会使用音效软件。例如,在演唱类直播中,主播伴随背景音乐演唱,这时主播往往希望为自己声音增加混响效果,营造出一种现场演唱的氛围;在搞笑类直播中,主播经常进行变声处理,女声变男声,男声变女声,或者变成机器人的声音等。
想要实现这些效果,需要直播软件对采集到的声音进行处理,为了让主播实时听到处理后的声音效果,以便根据效果进行调整,直播软件需要提供低延时回放,将效果呈现给主播。因此,直播软件背后的声音处理方案就起到了非常关键的作用。目前针对不同的操作系统,如苹果的iOS和谷歌的Android,有着为数众多的不同方案,效果不一。金山云作为视频云行业的领跑者,提供的声音处理方案,以出色的声音效果,赢得了众多移动直播APP的青睐。下面就以金山云直播SDK集成的苹果AudioUnit系列API方案为例,为各位详解基于iOS系统的移动直播音效,是如何实现的。
AudioUnit特点解析
从实际效果上说,苹果AudioUnit系列API方案,要比针对谷歌Android系统的跨平台声音处理库libsox等方案要好。一个原因在于,对于音效处理,苹果提供了非常丰富的音频API,涵盖采集、处理、播放各个环节,并按照需求的层次进行了分组。
说明: 图1. Core Audio Overview
苹果iOS系统音频框架概览
从上图中可以看到,离底层驱动和硬件最近的就是AudioUnit系列API。与其它声音处理方案相比,AudioUnit包含以下这些优缺点:
优点:
–低延时,从采集到播放回环可到10ms这一级别
–动态变更配置组合
–直接获得后台执行权限
–CPU资源消耗较少
缺点:
–专有概念比较多,接口复杂
–提供C风格API
由于AudioUnit并不完美,特别是专有概念比较多,接口也比较复杂,因此如果技术薄弱,在开发时难度会很大,金山云直播SDK解决了开发难度大等问题,这也是金山云SDK倍受欢迎的原因之一。
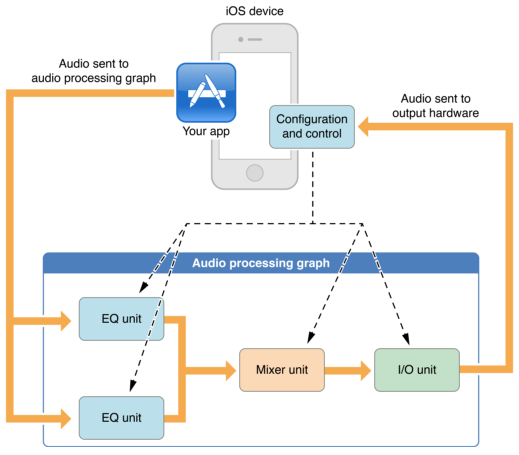
AudioUnit这个名字比较形象,它的主体是一系列单元节点(unit),不同的单元节点可实现不同的功能,将一个或多个单元节点添加到AUGraph(全称是Audio Processing Graph,把各个unit组合在一起,起到管理作用)中,并建立单元节点之间的连接,音频数据顺次通过各个节点,即可完成对声音的采集、处理和播放。如下图所示,AUGraph显示出了这个音频处理系统的构成,提供了启动和停止处理系统的接口。
说明: 图2. AudioUnit in iOS
AudioUnit示意图
如下方表格所示,苹果iOS系统提供了四类单元节点:
purposeAudio units
Effecteg. Reverb
mixingeg. Multichannel Mixer
I/Oeg. Remote I/O
Format conversioneg. Format Converter
其中,I/O主要负责设备,比如采集和播放;Mixing负责将不同来源的音频数据进行混合;Effect负责对音频数据进行音效处理,Format Conversion负责格式转换,比如重采样等。这里有个优化的点,由于Multichannel Mixer本身就有格式转换的功能,输入和输出的音频数据格式可以不同,因此利用这一点,可以节省一个格式转换单元。
AudioUnit中的音频采集
在直播应用中,我们主要使用Remote I/O unit进行采集。由于一个AUGraph中只允许有一个I/O unit,因此Remote I/O需要同时负责采集和播放。当用户开启耳返功能时,需要将采集到的声音,经过处理后再送回当前节点直接播放,这样可将采集和播放的延时控制在50ms以内,主播和观众才不会察觉到声音的延时。基本步骤如下(以下五个过程,均可在苹果官方文档中找到具体说明和代码示例):
1.实例化AUGraph,添加units;
2.配置每个AudioUnit属性;
3.设置渲染回调函数(Render Callback Function);
4.建立units连接;
5.启动AUGraph。
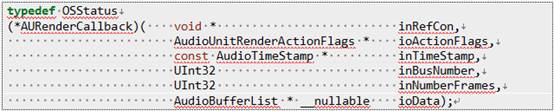
其中第4步较为关键,也就是设置渲染回掉函数,以下是该回掉函数的函数声明:
说明: 1
如上图所示,AudioUnit每次都会处理一段音频数据,每次处理完成一段数据的时候,此前设置的回调函数就会被调用一次。在这个回调函数中,通过AudioUnit的AudioUnitRender,可从AUGraph中的某个节点中,获取一段处理后的音频PCM数据。同时,如果需要进行耳返播放,在这个回调中,也需要将取得的音频数据送入到回调函数的最后一个参数ioData对应的buffer中。
在设置单元节点属性时,需要注意里面包含的一些公共属性。例如音频格式属性和MaximumFramesPerSlice。如果音频格式设置错误,容易出现AUGraph启动失败、声音异常等问题。在使用iOS内置的麦克风或有线耳机时,设备支持的采样率较高,44.1KHz可正常工作,整条音频通路基本都采用44.1KHz。当使用蓝牙设备时,一般蓝牙设备无法支持44.1KHz进行采集和播放,通常是16KHz甚至更低,这会导致I/O Unit无法继续使用之前的配置,需要按照实际支持的采样率进行配置。
AudioUnit还要求两个单元衔接处的音频数据格式必须保持一致,当AUGraph中不同unit支持的格式不同时(比如在支持蓝牙设备或者使用回声消除模块时,I/O unit要求的格式和其它单元可能会不同),此时就需要分别设置格式,并通过unit或mixer unit对格式进行转换。
如果MaximumFramesPerSlice设置错误,可能会出现声音异常。MaximumFramesPerSlice表示的是每次回调送入或取出的音频数据的长度,在AUGraph所有节点的这个属性,也需要保持一致,否则会导致其中一些unit丢弃数据而出现声音异常。
AudioUnit中的音效处理
这里所谓的音效处理,主要是指对原本的声音进行改变,比如混响效果,变声效果等。需要用到和数字信号处理有关的一系列时间和频域工具,将PCM数据输入,经过运算后得到变化后的声音。
混响效果
我们在音乐厅、剧院、礼堂等比较空旷的室内说话或唱歌时,能听到和平时不同的声音,原因是声音在墙壁上多次反射后叠加在一起,就有了混响的效果。在声音处理的过程中,可以人为将声音缓存起来,延时一定时间后,和原声音叠加,这样就能够模拟出混响效果。
AudioUnit提供了kAudioUnitSubType_Reverb2负责实现混响效果的生成,将该单元节点接入到AUGraph中之后,配置参数即可实现混响效果。虽然混响原理比较简单,但为了模拟自然界中的实际音效,这个计算过程还是相当复杂的,因为需要模拟大小不一的空间,不同材质的墙壁,包括障碍物的多少,都需要输入很多参数参与运算。对此,iOS的reverb unit提供了七种参数。金山云SDK在直播应用中,可提供四种不同场景的模拟(录音棚、演唱会、KTV、小舞台),主要是通过调整如下参数实现的:
kReverb2Param_DryWetMix混响效果声音的大小,与空间大小无关,只与空间内杂物多少以及墙壁和物体的材质有关;
kReverb2Param_DecayTimeAt0Hz/kReverb2Param_DecayTimeAtNyquist整个混响的总长度,与空间大小有关,越空旷,时间越长。
变声效果
变声效果是在频域上对人的声音进行处理,例如男声一般比较低沉,女声比较尖锐,这个主要说的是音调,而通过对声音音调的调整,可以让低沉的男声听上去像尖锐的女声。iOS提供的kAudioUnitSubType_NewTimePitch这一单元节点,即负责音调的调整。值得注意的是,kAudioUnitSubType_NewTimePitch不是输入Effect类,而是属于FormatConverter类,通过设置TimePitch unit的kNewTimePitchParam_Pitch属性即可。
说明: 2
如上图所示,变男声,需要强化突出低沉的特点,将音调调低,设置负数参数即可;
变女声,需要强化突出尖锐的特点,将音调调高,设置正数即可;
机器人的音效是一个组合效果,在很多科幻电影中,机器人音调比较高,而且有重音,因此我们采用了TimePitch unit + Delay unit的方式。Delay unit也是iOS提供的一个将声音延时叠加的单元节点,比混音要简单很多,只有单次叠加;
庄严宏大音效一般自带回声,而且较男性化,因此金山云选择了TimePitch unit + Reverb unit的方式实现。
这里推荐一个调节音效的参考软件voxal voice changer。大家可以在这个软件上将不同的工具组件进行组合,通过调试参数,即可实时听到参数对应的结果,效果满意后再移植到AudioUnit中。
说明: 图3 voixal voice changer
voixal voice changer软件截图
以上就是在iOS移动设备直播时的音频采集过程中,采用AudioUnit中的音效组件实现混响和变声效果的大致过程。金山云的直播SDK目前已集成此功能,深受直播行业客户的欢迎。实际上,AudioUnit还有很多功能没有被挖掘出来,比如可将背景音乐、混音、回声消除等其他移动多媒体音频相关的功能纳入到这个框架中,对此,金山云正在深入探索,希望带给直播用户更多更好的体验。
第四十一届CIO班招生
国际CIO认证培训
首席数据官(CDO)认证培训
责编:chenjian
免责声明:本网站(http://www.ciotimes.com/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等)版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。