说人工智能找到第二个太阳系
有点小牵强
日前谷歌CEO桑达尔·皮查伊(Sundar Pichai)在推特发布了谷歌AI团队与NASA合作的成果,运用“机器学习”能够从15000个讯号中正确地辨识出行星,正确率达到96%。而NASA发布的新闻稿,则是把重心放在行星狩猎计划Transiting Exoplanet Survey Satellite(TESS)以及Kepler-90这个拥有8个行星的星系特性上。
国内某著名科技自媒体则是以《重大发现!NASA和谷歌共同宣布发现“第二个太阳系”,AI扮演至关重要之角色》为题进行报道的。
太阳系不是有九大行星吗?实际上在2006年8月24日国际天文联合会议中,将因过去测量有误,误以为它比地球大,后来才发现它比月球还小的冥王星,由于体重不足被除名降格为矮行星。
这次通过“机器学习”找到两个星系,除了Kepler-90之外,另一个只有6颗行星在1000光年外的Kepler-80因为缺乏故事只能黯然做配角,我想这次NASA应该是要好好感谢国际天文联合会议,因为若不是他们英明地开除了冥王星,这场记者会恐怕还要等久一点才能开。
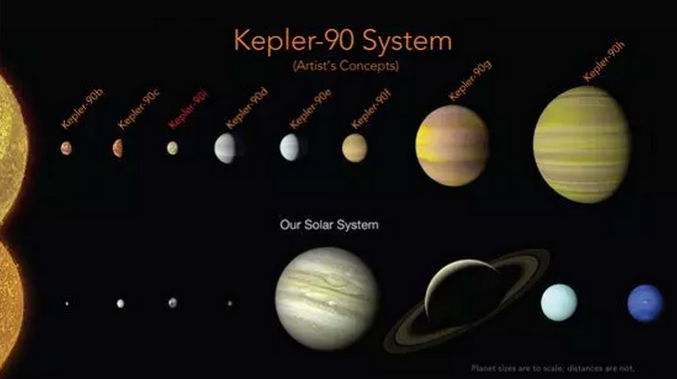
“第二个太阳系”的概念本身就是一个故事,是凑到了8颗行星的星系所以刚好借助这个概念来发布新闻,这和之前发布的第二个地球Kepler-452b其实是完全一样的概念,其实大家都清楚宇宙中肯定会有刚好8颗行星的星系,只不过这次特别用“第二个太阳系”的概念再度包装。
那人工智能扮演甚么样的角色呢?我们是如何知道数千光年外星球的信息的?是如何发现这些不会发光的行星的?其实利用的是当行星经过星系的恒星时,不会发光的行星自然会小区域地遮挡恒星的光芒,这个就是我们太阳系常见到的“凌日”现象,透过光芒被遮挡的程度以及变化速率,就能够推算出遮挡星体的体积以及运动速度,进而根据遮挡的类型来推断这星系中有几颗行星。但是会造成亮度变化的不只是行星,像双恒星系统也有可能会产生亮度变化,如何从大量的亮度变化数据中找出真正的行星就是一个大难题。
这对人类来说非常困难,但是对机器而言却不成问题。各位可以发现,有趣的是在国外的媒体几乎都是用“机器学习”,或者是谷歌Tensorflow技术,或者是谷歌使用神经网络来描述这个狩猎行星的机器帮手,但是鲜少有人用“深度学习”或是“人工智能”来描述这一过程。
其实猫腻就在于,对这些数据进行分析是个再简单不过的分类问题,而仔细检视谷歌发布的论文以及在GitHub上面发布的代码(解释附在文后),就可以知道里面用的都是很传统的旧型神经网络,里面虽然有用现代机器视觉常用的卷积神经网络,但是只有使用最简单的一维卷积,而且从实验结果来看,用传统神经网络和一维卷积的效果几乎没有差别。也就是说,这个发现要扯到人工智能,真的是有点小牵强。
人工智能算法的可怕之处其实在这!
当然,“人工智能”的威力不只是在找寻星系上,自然语言理解(NLU, Nature Language Understanding)是深度学习的重要任务之一,但是近期有些研究逆天,试图让深度学习去学主宰这个世界运作规律的语言。例如有研究团队将基因碱基做为单词,基因序列做为句子,来找出藏在基因中的文法,希望透过新技术能理解潜藏在句子中的语意,并用它识别潜在的遗传疾病的特征或是找寻治愈的契机。
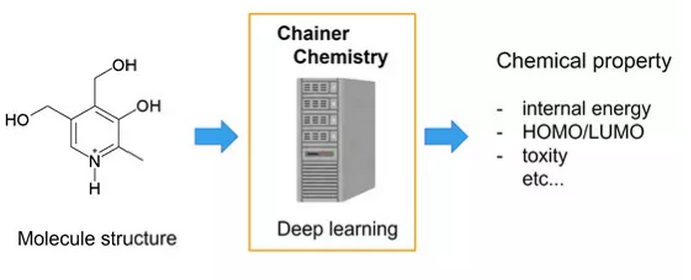
不仅是基因工程,我们都知道药物开发周期是相当漫长的,一个新药可能得耗费十几年的时间才能完成,也因此制药工程开始使用了深度学习,以有机物结构做为单词,有机分子做为语句,而语意正是指这些化学分子的药理特性。听起来是幻想?谷歌大脑在今年推出了“Neural Message Passing for Quantum Chemistry” (《量子化学中的神经信息传递》)这篇论文,可以说是探讨化学分子语言理论的奠基之作,通过人工智能助力,让我们能够读懂化学分子的文法,并据此找出更快取得新药候选清单的方法。
此外,最近我关注到了一篇社会新闻,就是主演神奇女侠的女星姬嘉铎(Gal Gadot)被热传拍摄了成人片。当然这个事件并非是女星不爱惜羽毛,而背后其实是人工智能搞的鬼。
在这两年的人工智能技术中,一个名为“生成式对抗网络”(GAN, Generative Adversarial Networks)的神经网络训练技巧大为风行。它的概念很简单也颇变态,就是让一个生成模型不断地制造假图片,而另一个识别模型用来指出假图片与真图片混合样本里那些是假图片,两个模型的损失函数都链接到对方的表现上,也就是当对方越强时,自己会变得更强(天啊,每次讲到这段我就想起蛊毒),最后通常是生成模型获胜,也就是得到一个可以做出几乎可以以假乱真的假图片的生成模型,最恶心的是,这个生成模型压根没看过真图片,它为何能做到几可乱真,其实纯粹只是根据识别模型的反应来推测的。

在GAN里面有一种结构的变体称为Cycle GAN,简单的来说它能做到像素层级的物体视觉翻译。从技术的角度看,中文翻译成英文其实与马变成斑马的概念是类似的,都是一种函数的转换。而Cycle GAN的特别之处在于以前训练模型需要成对的数据(一个句子同时有中文版与英文版),但是它可以不需要成对数据,只要有个别足够的数据就能够进行视觉翻译。原本的论文中展示了马变斑马以及苹果变橘子的神奇效果,但是由于它对于训练样本的弹性,这意味着我们只要手上有足够的神奇女侠女星影像以及成人片的数据,就能够做出神奇女侠拍成人片的效果。

2015年微软藉由152层的神经网络首度在识别的任务中超越了人类视觉。当一个连深度学习都无法识别的假图片,对人类来说就比真实还要真了。未来的世界可能会是一个真假难分的世界,所有我们现在做为法律证据的基础都可能被冲击,我认为这些算法带来的影响恐怕远胜于找到几千光年外的一个太阳系。
第四十一届CIO班招生
国际CIO认证培训
首席数据官(CDO)认证培训
责编:houlimin
免责声明:本网站(http://www.ciotimes.com/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等)版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。





