
在本文中,我们将重点关注构造模型的个性化,阐述这个模型的原理,以及如何使 Photon-ML 普及到数亿的用户。
简介
推荐系统是一种自动化的计算机程序,它可以根据不同的内容给用户匹配相应的项目。这样的系统无处不在,已经成为我们日常生活不可或缺的一部分。例如像 Amazon 这样会向用户推荐产品的网站,像雅虎这样会向用户推荐内容的网站,像 Netflix 这样会向用户推荐电影的网站,像在 LinkedIn 上会给用户推荐工作等等。考虑到用户首选项的显著的异构性,提供个性化推荐是此类系统成功的关键。
为了达到这个目标,使用机器学习模型来评估那些反馈用户偏好的数据是至关重要的。这些模型是利用从用户之前与项目的互动中获得的大量高频数据来构建的。它们本质上属于统计学范畴,并且涉及到诸如序贯决策的过程、高度维度分类数据的交互建模以及开发可拓展的统计测量方法等领域的难点。这一领域的新方法需要计算机科学家、研究机器学习的学者、统计学家、负责优化的专家、系统专家以及人工智能领域的专家之间的密切合作。这是大数据最令人兴奋的应用之一。
LinkedIn 上的许多产品都授权给推荐系统了。这些系统的核心组件是一个易于使用和灵活的机器学习库,称为 Photon-ML,它是我们的生产力、敏捷度以及开发人员幸福的关键。我们已经开源了大部分 Photon-ML 所使用的算法。在本文中,我们重点关注构造模型的个性化方面,并阐述这个模型原理,以及如何使 Photon-ML 能普及到数亿的用户。
Photon-ML 的个性化模型
在 LinkedIn ,我们通过 Photon-ML 观察到,在许多产品领域的用户参与度和其他业务指标的显著提升。为了提供一个具体的例子,请注意我们如何使用广义相加混合效应 (GAME) 模型来进行个性化的工作推荐,在我们的线上 A/B 实验中,它为求职者提供了 20% 到 40% 的工作申请。
LinkedIn 求职网页快照
作为世界上最大的职业社交网络,LinkedIn 为其超过 5 亿的会员提供了独特的价值定位,给他们的职业发展提供各种各样的机会。我们提供的最重要的产品之一是求职主页,它是为了那些想要申请一份好工作的用户而服务的中心场所。图 1 是 LinkedIn 求职主页的一个快照。页面上的一个主要模块是“您可能感兴趣的工作”,根据用户们的公开简介数据和之前在站点上的活动,向他们推荐相关的工作缩略图。如果一个成员对推荐的工作感兴趣,她可以点击它进入职位详情页面,在这个页面中,与之相关的工作岗位显示的信息包括职位名称、描述、职责、要求的技能和资历。这份职位详情页面还有一个“应用”按钮,可以让用户在 LinkedIn 上或公司的网站上点击一下就可以申请这份工作。LinkedIn 的就业业务的一个关键成功指标是职位应用点击量(即:点击“应用”按钮的点击次数)。
我们的模型的目标是准确地预测一个成员点击推荐工作的“应用”按钮的概率。直观上,该模型由三个组件组成(子模型):
· 一个全局模型,它抓住了用户如何申请工作的一般行为
·一个特殊成员的模型,赋于特殊成员一些参数(从数据中学习)以捕获成员那些偏离了一般行为的个人行为
·一个特殊职位的模型,赋予特殊职位一些参数(从数据中学习)以捕获职位偏离一般行为的的独特行为
与许多推荐系统的应用程序一样,我们在每个成员或工作的数据量中观察到大量的差异性。网站上有新成员(因此几乎没有数据),也有一些有强烈求职意向而且过去曾申请过很多工作的成员。同样地,从职位上说,既有受欢迎的,也有不受欢迎的。我们希望利用特殊用户模型针对之前对不同职位有许多响应的用户。另一方面,如果成员没有太多的过去的响应数据,我们希望能够回到捕获一般行为的全局模型来针对这些成员。
现在让我们深入了解一下 GAME 模型是如何实现这样一种个性化的。让 ymjt 表示成员 m 是否会在内容t中申请工作j的二进制响应,其中内容通常包括显示职业的工作时间和位置。我们使用 qm 表示成员 m 的特征向量,包括获取成员的公开简介的特征形象,如成员的名字、工作职能、教育历史,行业,等等。我们用sj 表示职位的特征向量,其中包括获取工作职位的特征,如职位、需要的技能和经验,等。让 xmjt 代表总体特征向量,可包括 qm 和 sj 主要特征的影响,qm 和 sj 的叉积表示成员和工作特性之间的交互作用,以及内容的特性。我们假设 xmjt 不包含成员 id 或项目 id 作为特性,因为 IDs 将不同于常规特性。用逻辑回归方法预测成员 m 申请工作j的可能性的 GAME 模型是:
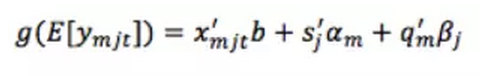
(1)
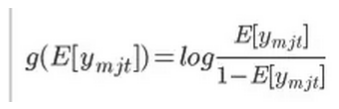
是链接功能,b 是全局系数向量(在统计学文献中也称为固定效应系数),αm 和 βj 系数向量是分别用于成员 m 和工作 j,αm 和 βj 被称为随机效应系数,它捕获了成员 m 对不同项目的个人偏好和工作j对不同成员特性的吸引力。对于一个在过去对不同项目有很多反应的成员 m,我们能够准确地估计她的个人系数向量并提供个性化的预测。另一方面,如果成员 m 没有太多的过去的响应数据,那么 αm 的后平均值将接近于零,而成员m的模型将回落到全局固定效应组件 x'mjtb.。同样的行为也适用于每个职业系数向量 βj。
Photon-ML:用于构建个性化模型的可拓展平台
为了在 Hadoop 集群上使用大量数据来训练模型,我们在 Apache Spark 上开发了 Photon-ML 。设计可拓展算法的一个主要挑战是,要从数据中学习的模型参数的数量是巨大的(例如,数以百亿)。如果我们使用标准的机器学习方法(如Spark所提供的 MLlib)来训练模型,那么网络通信会花费无法预算的成本去更新大量参数的。大量的参数主要来自于特殊用户和特殊职位的模型。因此,使算法可拓展的关键是避免在特殊用户的和特殊职位的模型中通信或者传播大量的参数。
通过应用基于平行坐标下降法(PBCD),我们解决了大规模的模型训练问题,它迭代地训练全局模型、特殊用户的模型和特殊职位的模型直到收敛。使用标准的分布式梯度下降法对全局模型进行训练。对于特殊用户的模型和特殊职业的模型,我们设计了一个模型参数更新方案,这样特殊工作的和特殊职业的模型中的参数不需要通过集群中的机器进行通信。相反,每个训练实例的部分分数是通过机器进行交流的。这大大降低了通信成本。PBCD 可以很容易地应用于有着不同类型子模型的模型。
结论和未来展望
在本文中,我们简要介绍了如何使用 Photon-ML 来实现个性化的推荐。由于本文的篇幅限制,我们跳过了许多优化的趣味和细节的完善。我们强烈建议我们的读者去查看开源的 Photon-ML 报导。在 LinkedIn 上,我们致力于打造最先进的推荐系统。我们已经为 Photon-ML 做了令人激动的计划。在不久的将来,我们计划向 Photon-ML 添加更多的建模功能,包括树型模型和不同的深度学习算法,以捕获非线性和更深层的表示结构。
第四十一届CIO班招生
国际CIO认证培训
首席数据官(CDO)认证培训
责编:houlimin
免责声明:本网站(http://www.ciotimes.com/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等)版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。




