集成算法(Ensemble Algorithms)综述
严格意义上来说,这不算是一种机器学习算法,而更像是一种优化手段或者策略,它通常是结合多个简单的弱机器学习算法,去做更可靠的决策。有人把它称为机器学习中的“屠龙刀”,非常万能且有效,集成模型是一种能在各种的机器学习任务上提高准确率的强有力技术,集成算法往往是很多数据竞赛关键的一步,能够很好地提升算法的性能。哲学思想为“三个臭皮匠赛过诸葛亮”。拿分类问题举个例,直观的理解,就是单个分类器的分类是可能出错,不可靠的,但是如果多个分类器投票,那可靠度就会高很多。
现实生活中,我们经常会通过投票,开会等方式,以做出更加可靠的决策。集成学习就与此类似。集成学习就是有策略的生成一些基础模型,然后有策略地把它们都结合起来以做出最终的决策。集成学习又叫多分类器系统。
集成方法是由多个较弱的模型集成模型组,一般的弱分类器可以是DT, SVM, NN, KNN等构成。其中的模型可以单独进行训练,并且它们的预测能以某种方式结合起来去做出一个总体预测。该算法主要的问题是要找出哪些较弱的模型可以结合起来,以及如何结合的方法。这是一个非常强大的技术集,因此广受欢迎。
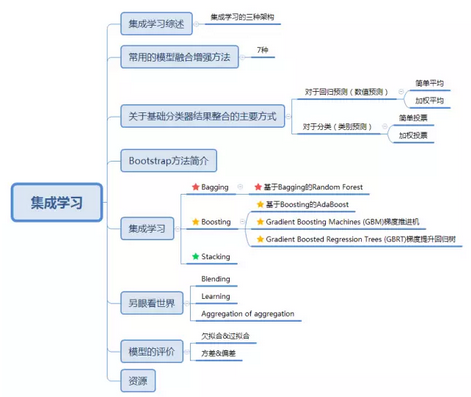
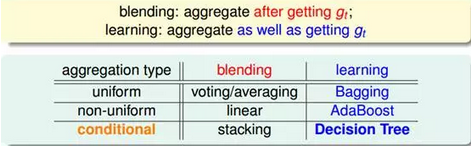
集成算法家族强大,思想多样,但是好像没有同一的术语,很多书本上写得也不一样, 不同的学者有不同的描述方式,最常见的一种就是依据集成思想的架构分为 Bagging ,Boosting, Stacking三种。国内,南京大学的周志华教授对集成学习有深入的研究,其在09年发表的一篇概述性论文《Ensemple Learning》对这三种架构做出了明确的定义。
算法鸟瞰
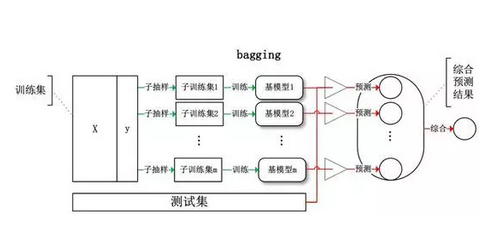
Bagging:基于数据随机重抽样的分类器构建方法。从训练集从进行子抽样组成每个基模型所需要的子训练集,对所有基模型预测的结果进行综合产生最终的预测结果 :
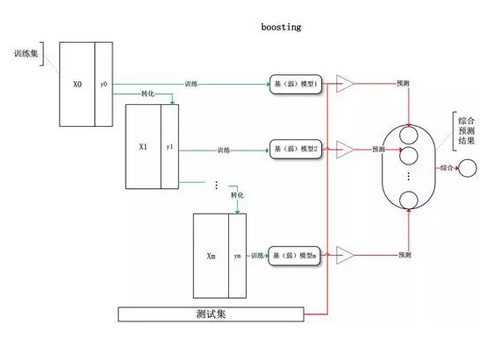
Boosting:训练过程为阶梯状,基模型按次序一一进行训练(实现上可以做到并行),基模型的训练集按照某种策略每次都进行一定的转化,每次都是提高前一次分错了的数据集的权值,最后对所有基模型预测的结果进行线性组合产生最终的预测结果 :
Stacking:将训练好的所有基模型对训练基进行预测,第j个基模型对第i个训练样本的预测值将作为新的训练集中第i个样本的第j个特征值,最后基于新的训练集进行训练。同理,预测的过程也要先经过所有基模型的预测形成新的测试集,最后再对测试集进行预测:
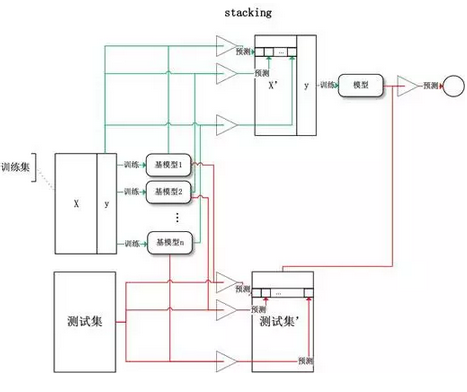
Stacking算法分为2层,第一层是用不同的算法形成T个弱分类器,同时产生一个与原数据集大小相同的新数据集,利用这个新数据集和一个新算法构成第二层的分类器。
常用的模型融合增强方法
Bagging (Bootstrapped Aggregation)
Random Forest
Boosting
AdaBoost (Adaptive Boosting)
Gradient Boosting Machines (GBM)梯度推进机
Gradient Boosted Regression Trees (GBRT)梯度提升回归树
Stacked Generalization (blending)层叠泛化
关于基础分类器结果整合的主要方式
1. 对于回归预测(数值预测)
简单平均(Simple Average),就是取各个分类器结果的平均值。

加权平均(Weighted Average)
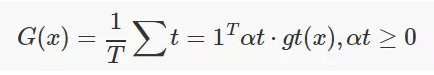
2. 对于分类(类别预测)
简单投票(Majority Voting):就是每个分类器的权重大小一样,少数服从多数,类别得票数超过一半的作为分类结果。
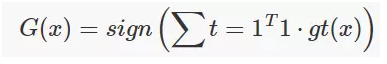
加权投票(Weighted Majority Voting):每个分类器权重不一。
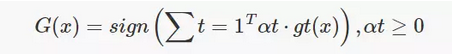
概率投票(Soft vote):有的分类器的输出是有概率信息的,因此可用概率投票。
集成学习的关键有两点:
如何构建具有差异性的分类器 ,
如何多这些分类器的结果进行整合。
基学习器之间的性能要有较大的差别,否则集成效果会很不好,也就是要保证多样性(Diversity),基学习器可以是DT, SVM, NN, KNN等,也可以是训练过程不同的同一种模型,例如不同的参数,不同的训练集,或者不同的特征选择等。
Bootstrap方法简介
Bootstrap方法是非常有用的一种统计学上的估计方法。 Bootstrap是一类非参Monte Carlo方法,其实质是对观测信息进行再抽样,进而对总体的分布特性进行统计推断。首先,Bootstrap通过重抽样,避免了Cross-Validation造成的样本减少问题,其次,Bootstrap也可以创造数据的随机性。Bootstrap是一种有放回的重复抽样方法,抽样策略就是简单的随机抽样。
基于Bootstrap 的Bagging 算法
Bagging(Bootstrapped Aggregation的简称)对于给定数据处理任务,采用不同的模型、参数、特征训练出多个模型,最后采用投票或者加权平均的方式输出最终结果。基学习器可以是相同的模型,也可以是不同的,一般使用的是同一种基学习器,最常用的是DT决策树。
Bagging通过对原数据集进行有放回的采样构建出大小和原数据集D一样的新数据集D1,D2,D3……,然后用这些新的数据集训练多个分类器g1,g2,g3…因为是有放回的采样,所以一些样本可能会出现多次,而有些样本会被忽略,理论上新的样本会包含67%的原训练数据。
Bagging通过降低基分类器的方差改善了泛化能力,因此Bagging的性能依赖于基分类器的稳定性,如果基分类器是不稳定的,Bagging有助于降低训练数据的随机扰动导致的误差,但是如果基分类器是稳定的,即对数据变化不敏感,那么bagging方法就得不到性能的提升。
算法流程如下:

基于Bagging的Random Forest
随机森林(Random Forest)是许多决策树的平均,每个决策树都用通过Bootstrap的方式获得随机样本训练。森林中的每个独立的树都比一个完整的决策树弱,但是通过将它们结合,可以通过多样性获得更高的整体表现。
随机森林会首先生成许多不同的决策树,每棵树变量的个数可以为(K为可用变量的个数),这样能够显著的加速模型的训练速度。一般的基础分类器的个数为500棵或者可以更多。
随机森林具有Self-testing的特性,因为随机森林是通过Bootstrap的方式采样,理论上往往会有大约1/3的原始数据没有被选中,我们叫做OOB(out of bag),而这部分数据刚好可以用来做测试,类似于Cross-Validation的作用。
随机森林是当今机器学习中非常流行的算法。它是一种“集群智慧”,非常容易训练(或构建),且它往往表现良好。
随机森林具有很多的优点:
所有的数据都能够有效利用,而且不用人为的分出一部分数据来做cross-validation
随机森林可以实现很高的精确度,但是只有很少的参数,而且对于分类和回归都适用
不用担心过拟合的问题,
不需要事先做特征选择,每次只用随机的选取几个特征来训练树
它的缺点是:
相比于其他算法,其输出预测可能较慢。
集成学习
Boosting
Boosting(Adaptive Boosting的简称),基于错误提升分类器性能,通过集中关注被已有分类器分类错误的样本,构建新分类器并集成。其思想为模型每次迭代时通过调整错误样本的损失权重,提升对数据样本整体的处理精度。Boosting与Bagging 相比来说最大的区别就是 Boosting是串行的,而Bagging中所有的分类器是可以同时生成的,之间没有什么关系,而Boosting中则必须先生成第一个分类器,然后根据第一个分类器的结果生成第二个分类器,依次往后进行。
| 项目 | Bagging | Boosting | | -------- | -----: | :----: | | 结构 | 并行 | 串行 | | 训练集 | 独立 | 依赖 | | 测试 | 可并行 | 需串行 | | 作用 | 减小variance | 减小bias |
核心思想是通过改变训练集进行有针对性的学习。通过每次迭代,增加错误样本的权重,减小正确样本的权重。知错就改,越来越好。
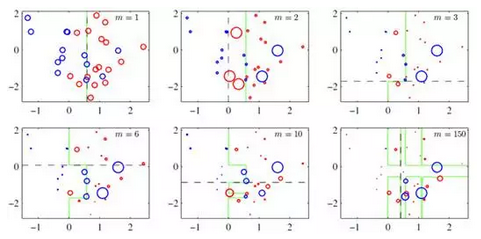
上图(图片来自prml p660)就是一个Boosting的过程,绿色的线表示目前取得的模型(模型是由前m次得到的模型合并得到的),虚线表示当前这次模型。每次分类的时候,会更关注分错的数据,上图中,红色和蓝色的点就是数据,点越大表示权重越高,看看右下角的图片,当m=150的时候,获取的模型已经几乎能够将红色和蓝色的点区分开了。
算法流程如下:
增加前边学错样本的权重,减小已经判断正确的样本的权重,有点亡羊补牢,知错就改的意思,进行有针对性的学习。理论上,Boosting 可以生成任意精确的分类器,而基础学习器则可以任意弱,只需要比瞎猜好一点就OK~
AdaBoost
AdaBoost 是Boosting中最具代表性的算法。AdaBoost 是一种Boosting方法,与Bagging不同的是,Adaboost中不同的子模型必须是串行训练获得,每个新的子模型是都根据已训练出的模型性能来进行训练的,而且Boosting算法中基学习器为弱学习,可以理解为只比随机猜测好一点,在二分类情况下,正确率略高于0.5即可。
AdaBoost中每个训练样本都有一个权重,初始值都为Wi=1/N。Adaboost中每次迭代生成新的子模型使用的训练数据都相同,但是样本的权重会不一样。AdaBoost会根据当前的错误率,按照增大错误样本权重,减小正确样本权重的原则更新每个样本的权重。不断重复训练和调整权重,直到训练错误率或基学习器的个数满足用户指定的数目为止。Adaboost的最终结果为每个弱学习器加权的结果。
算法流程如下:

AdaBoost 优点:
很容易实施
几乎没有参数需要调整
不用担心过拟合
缺点:
公式中的α是局部最优解,不能保证是最优解
对噪声很敏感
林轩田老师课程中AdaBoost的算法流程可能更加容易理解一些。

Gradient Boosting Machines (GBM)梯度推进机
梯度提升和随机森林类似,都是由弱决策树构成的。最大的区别是,在梯度提升中树是被一个接一个相继训练的。每个随后的树主要用被先前树错误识别的数据进行训练。这使得梯度提升更少地集中在容易预测的情况并更多地集中在困难的情况。
Gradient Boost与传统Boost的区别在于每个新的模型是为了使之前的模型的残差往梯度方向减少。Gradient Boost与传统的Boost的区别是,每一次的计算是为了减少上一次的残差(residual),而为了消除残差,我们可以在残差减少的梯度(Gradient)方向上建立一个新的模型。所以说,在Gradient Boost中,每个新的模型的建立是为了使得之前模型的残差往梯度方向减少,与传统Boost对正确、错误的样本进行加权有着很大的区别。
梯度提升训练速度也很快且表现非常好。然而,训练数据的小变化可以在模型中产生彻底的改变,因此它可能不会产生最可解释的结果。
Gradient Boosted Regression Trees (GBRT)梯度提升回归树
首先应该说明的一点是,这个算法有很多名字,但其实是一样的~
Gradient Tree Boosting
GBRT (Gradient BoostRegression Tree) 梯度提升回归树
GBDT (Gradient BoostDecision Tree) 梯度提升决策树
MART (MultipleAdditive Regression Tree) 多决策回归树
Tree Net决策树网络
GBRT也是一种Boosting方法,每个子模型是根据已训练出的学习器的性能(残差)训练出来的,子模型是串行训练获得,不易并行化。GBRT基于残差学习的算,没有AdaBoost中的样本权重的概念。GBRT结合了梯度迭代和回归树,准确率非常高,但是也有过拟合的风险。GBRT中迭代的是残差的梯度,残差就是目前结合所有得到的训练器预测的结果与实际值的差值。
GBRT使用非常广泛的,能分类,能回归预测。GBRT是回归树,不是分类树。其核心就在于,每一棵树是从之前所有树的残差中来学习的。GBRT不是分类树而是回归树。
决策树分为回归树和分类树:
回归树用于预测实数值,如温度、用户年龄等
分类树用于分类标签值,如天气情况、用户性别等。
模型组合+决策树相关的算法有两种比较基本的形式 :随机森林与GBDT(Gradient Boost Decision Tree)。其他的比较新的模型组合+决策树的算法都是来自这两种算法的延伸。
算法流程如下:

Stacking
Wolpert在1992年的一篇论文中对 stacked generalization进行了介绍 , stacked generalization背后的基本思想是使用大量基分类器,然后使用另一种分类器来融合它们的预测,旨在降低泛化误差。
Stacking 主要分为两大部分。第一层就是传统的训练,训练出许多小分类器;第二层则是把这些小分类器的输出重新组合成为一个新的训练集,训练出来一个更高层次的分类器,目的就是寻找相应的权重或者它们之间的组合方式。
在训练第二层分类器时采用各基础分类器的输出作为输入,第二层分类器的作用就是对基础分类器的输出进行集成。
图释:
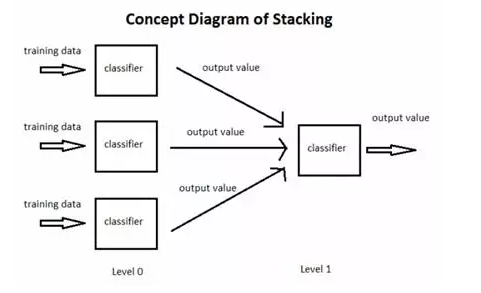
算法流程如下:
Stacking 就像是 Bagging的升级版,Bagging中的融合各个基础分类器是相同权重,而Stacking中则不同,Stacking中第二层学习的过程就是为了寻找合适的权重或者合适的组合方式。
值得注意的是,在Stacking的架构下,有一些经常出现的说法如Stacking, Blending , Stacked Generalization 很多文章也没有明确说明他们之间的关系。
如果不严格来区分的话,可以认为堆叠(Stacking),混合(Blending)和层叠泛化(Stacked Generalization)其实是同一种算法的不同名字罢了。在传统的集成学习中,我们有多个分类器试图适应训练集来近似目标函数。 由于每个分类器都有自己的输出,我们需要找到一个组合结果的组合机制,可以通过投票(大多数胜利),加权投票(一些分类器具有比其他权力更多的权威),平均结果等。
在堆叠中,组合机制是分类器(0级分类器)的输出将被用作另一个分类器(1级分类器)的训练数据,以近似相同的目标函数。基本上,让1级分类器找出合并机制。
Stacking, Blending and and Stacked Generalization are all the same thing with different names. It is a kind of ensemble learning. In traditional ensemble learning, we have multiple classifiers trying to fit to a training set to approximate the target function. Since each classifier will have its own output, we will need to find a combining mechanism to combine the results. This can be through voting (majority wins), weighted voting (some classifier has more authority than the others), averaging the results, etc.
另眼观世界
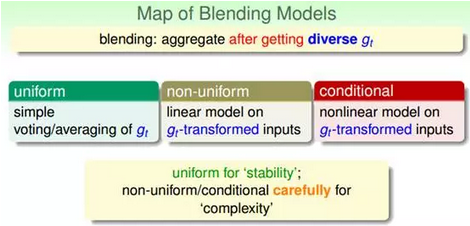
最后我们也可以按照林轩田老师课程中的讲述来对机器学习集成算法做一个归纳。集成模型主要分为两条主线,一条Blending 线,一条 Learning线。Blending 假设我们已经得到了各个基础分类器 ,learning 主要指我们面对的是一堆数据,需要一边获得基础分类器 ,同时一边学习融合它们的方法。
Blending框架
Learning框架
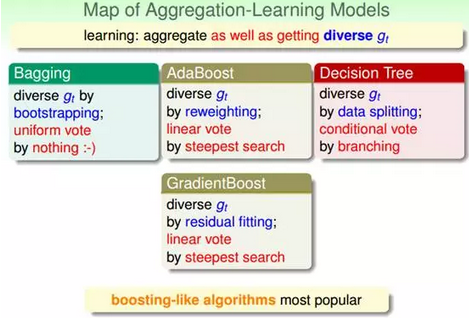
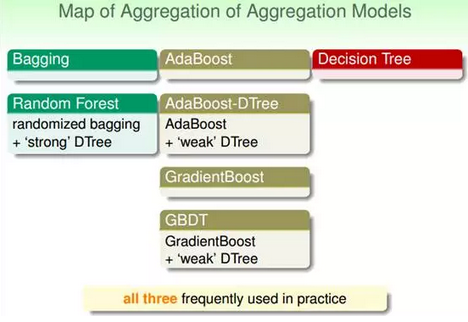
当然还有更加复杂一点的,就是集成的集成。
模型的评价
评价模型优劣的准则有很多。
欠拟合和过拟合是经常出现的两种情况,简单的判定方法是比较训练误差和测试误差的关系,当欠拟合时,可以设计更多特征来提升模型训练精度,当过拟合时,可以优化特征量降低模型复杂度来提升模型测试精度。
过拟合与欠拟合
图释:
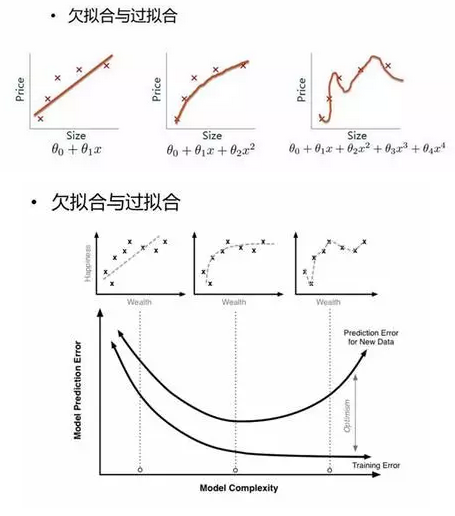
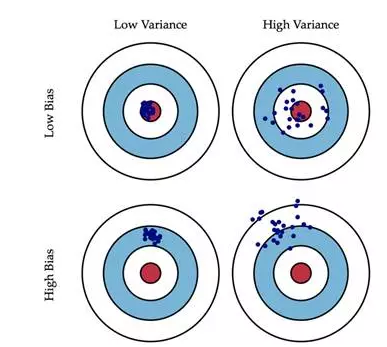
方差与偏差
机器学习模型的Bias和Variance分析, Understanding the Bias-Variance Tradeoff中的一副图生动形象地为我们展示了偏差和方差的关系:
简单来说,一个模型越复杂,对训练样本的拟合度会越高,其Bias会越小(训练误差小)。但是,由于对数据过于敏感,生成的模型的变化范围可能比较大(Variance较大),可能导致在测试数据上性能的不确定性较高。
第四十一届CIO班招生
国际CIO认证培训
首席数据官(CDO)认证培训
责编:houlimin
免责声明:本网站(http://www.ciotimes.com/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等)版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。