2016-09-01 09:05:53 来源:RFID世界网
▌什么是数据采集?
数据采集(DAQ), 又称数据获取,是指从传感器和其它待测设备等模拟和数字被测单元中自动采集信息的过程。数据分类新一代数据体系中,将传统数据体系中没有考虑过的新数据源进行归纳与分类,可将其分为线上行为数据与内容数据两大类。
线上行为数据:页面数据、交互数据、表单数据、会话数据等。
内容数据:应用日志、电子文档、机器数据、语音数据、社交媒体数据等。
大数据的主要来源:1)商业数据 2)互联网数据 3)传感器数据
▌数据采集与大数据采集区别
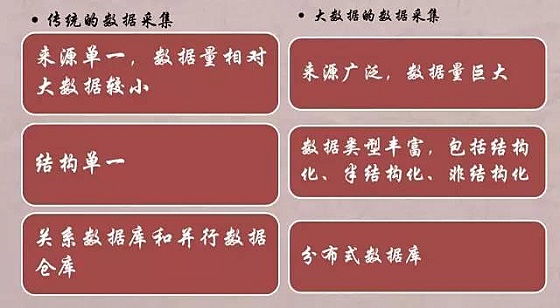
传统的数据采集来源单一,且存储、管理和分析数据量也相对较小,大多采用关系型数据库和并行数据仓库即可处理。对依靠并行计算提升数据处理速度方面而言,传统的并行数据库技术追求高度一致性和容错性,根据CAP理论,难以保证其可用性和扩展性。
▌大数据采集新的方法
系统日志采集方法
很多互联网企业都有自己的海量数据采集工具,多用于系统日志采集,如Hadoop的Chukwa,Cloudera的Flume,Facebook的Scribe等,这些工具均采用分布式架构,能满足每秒数百MB的日志数据采集和传输需求。
网络数据采集方法
网络数据采集是指通过网络爬虫或网站公开API等方式从网站上获取数据信息。该方法可以将非结构化数据从网页中抽取出来,将其存储为统一的本地数据文件,并以结构化的方式存储。它支持图片、音频、视频等文件或附件的采集,附件与正文可以自动关联。 除了网络中包含的内容之外,对于网络流量的采集可以使用DPI或DFI等带宽管理技术进行处理。
其他数据采集方法
对于企业生产经营数据或学科研究数据等保密性要求较高的数据,可以通过与企业或研究机构合作,使用特定系统接口等相关方式采集数据。
▌大数据采集平台
最后,再为大家介绍几款应用广泛的大数据采集平台,供大家参考使用。
1)Apache Flume
Flume 是Apache旗下的一款开源、高可靠、高扩展、容易管理、支持客户扩展的数据采集系统。 Flume使用JRuby来构建,所以依赖Java运行环境。
2)Fluentd
Fluentd是另一个开源的数据收集框架。Fluentd使用C/Ruby开发,使用JSON文件来统一日志数据。它的可插拔架构,支持各种不同种类和格式的数据源和数据输出。最后它也同时提供了高可靠和很好的扩展性。Treasure Data, Inc 对该产品提供支持和维护。
3)Logstash
Logstash是著名的开源数据栈ELK (ElasticSearch, Logstash, Kibana)中的那个L。Logstash用JRuby开发,所有运行时依赖JVM。
4)Splunk Forwarder
Splunk是一个分布式的机器数据平台,主要有三个角色:Search Head负责数据的搜索和处理,提供搜索时的信息抽取;Indexer负责数据的存储和索引;Forwarder,负责数据的收集,清洗,变形,并发送给Indexer。
免责声明:本网站(http://www.ciotimes.com/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等)版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。




