Hadoop与Storm的对比
Hadoop与Storm的对比
2017-09-30 11:15:31 来源:中国云计算  抢沙发
抢沙发
2017-09-30 11:15:31 来源:中国云计算
1、Hadoop上运行的是MapReduce jobs,而在Storm上运行的是topology。
2、 Hadoop使用磁盘作为中间交换的介质,而storm的数据是一直在内存中流转。
3、hadoop的数据源是HDFS上某文件夹下已经存在的TB级的大数据,待处理的数据是相对不变的;而Storm的数据源是实时新增的B或KB级的小数据,处理的数据是支持增加的。
4、一个MapReduce job数据处理完后会自动结束, 而一个topology数据处理完后会一直等待下一个数据的到来,不会自动停止(除非你手动强制停止)。
5、hadoop擅长批处理、吞吐量大、做全量数据的离线分析,Storm的优势是数据的实时分析,以实时性高被广泛应用,单位时间内的吞吐量要小于hadoop。
6、对比Hadoop的批处理,Storm是一个实时处理计算框架,是针对在线业务而存在的计算平台。同Hadoop一样Storm也可以处理大批量的数据,然而Storm在保证高可靠性的前提下还可以让处理进行的更加实时。Storm同样具备容错和分布计算这些特性。Storm易于扩展,随着业务的发展,数据量、计算量的增大,只需要添加机器和改变对应的topology(拓扑)设置。Storm使用Zookeeper进行集群协调,充分保证集群的稳定运行。Storm一旦递交topology就会一直运行,直到topology被废除或者被关闭。而在执行中出现错误时,也会由Storm重新分配任务,一个节点挂了不能影响我的应用。
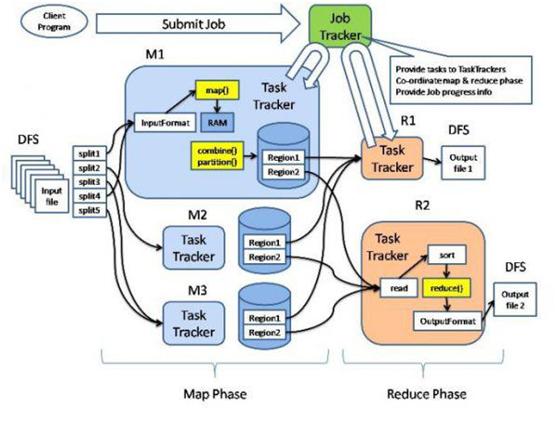
7、Hadoop下的Map/Reduce计算框架对于数据的处理流程是:
(1) 将要处理的数据上传到Hadoop的文件系统HDFS中。
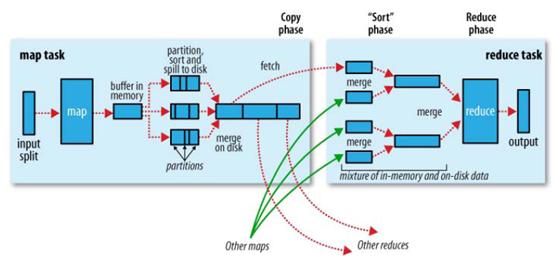
(2) Map阶段: 对于大量的数据进行切分,划分为M个16~64M的数据分片(可通过参数自定义分片大小)。调用Mapper函数:Master为Worker分配Map任务,每个分片都对应一个Worker进行处理。各个Worker读取并调用用户定义的Mapper函数处理数据,并将结果存入HDFS,返回存储位置给Master。一个Worker在Map阶段完成时,在HDFS中,生成一个排好序的Key-values组成的文件。并将位置信息汇报给Master。
(3)Reduce阶段:Master为Worker分配Reduce任务,他会将所有Mapper产生的数据进行映射,将相同key的任务分配给某个Worker。调用Reduce函数:各个Worker将分配到的数据集进行排序,并调用用户自定义的Reduce函数,并将结果写入HDFS。每个Worker的Reduce任务完成后,都会在HDFS中生成一个输出文件。
使用Hadoop需要先将数据put到Hdfs,按每16-64MB切一个文件的粒度来计算,1分钟已经过去了,Hadoop 开始计算时,开始调度任务又花了一分钟,然后作业运行起来,假设机器特别多,几钞钟就计算完,然后假设写数据库也花了很少的时间,这样从数据产生到最后可以使用已经过去了两分钟多。
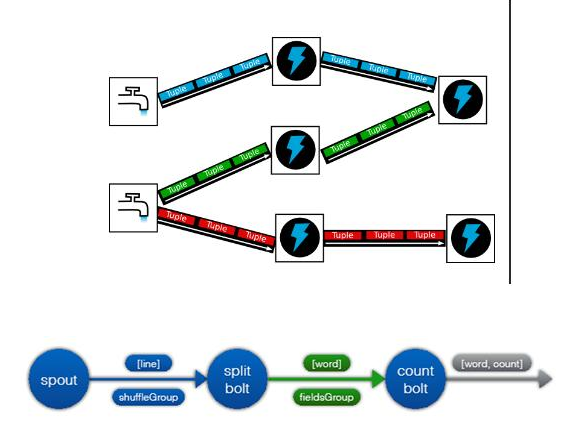
8、Storm是一个流式计算框架,对于数据的处理流程是:Storm将数据以Stream的方式,并按照Topology的顺序,依次处理并最终生成结果。
流计算是数据产生时,就有一个程序一直在监控数据,产生一行就通过传输系统发给流式计算系统,然后流式计算系统直接处理,处理完后直接写入数据库,每条数据从产生到写入数据库,可以在毫秒内完成。
第四十一届CIO班招生
国际CIO认证培训
首席数据官(CDO)认证培训
责编:lixiaojiao
免责声明:本网站(http://www.ciotimes.com/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等)版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。