3、大数据挖掘的方法、流程和场景
3.1大数据采集的特点
大数据应用的第一步就是采集数据。巧妇难为无米之炊,数据采集的完整性、准确性,决定了数据应用是否能真实可靠的发挥作用。大数据时代的数据采集有如下三个特点:
1) 数据采集以自动化手段为主,要尽量摆脱人工录入的方式;
2) 采集内容以全量采集为主,要摆脱对数据进行采样的方式;
3) 采集方式多样化、内容丰富化,摆脱以往只采集基本数据的方式。
从采集数据的类型上看,不仅要涵盖基础的结构化交易数据,还将逐步包括半结构化的用户行为数据,网状的社交关系数据,文本或音频类型的用户意见和反馈数据,设备和传感器采集的周期性数据,网络爬虫获取的互联网数据,以及未来越来越多有潜在意义的各类数据。
3.2常见数据采集技术
传统的数据采集方法包括人工录入、调查问卷、电话随访等方式,大数据时代到来后,一个突出的变化是数据采集的方法有了质的飞跃,下面所介绍的数据采集方式的突破直接改变着大数据应用的场景。
移动互联网的兴起让面向移动设备的数据采集技术有了迅速发展,目前使用最多的常称为Android或iOS的采集SDK(Software Develop Kit),这种技术能帮助统计APP的基础数据,包括用户数、活跃情况、流失比例、使用时长等;用户的位置、安装列表、通讯情况等通过授权也可以采集。网络爬虫是另一类广泛使用的互联网采集技术,常被用于进行大规模全网信息采集、舆情监控、竞品分析等领域。
图3:移动互联网和可穿戴传感器等新型数据采集技术蓬勃发展
物联网也和大数据息息相关,因为物联网的关键技术之一是无线射频标签(RFID):当安装有RFID微型标签的读卡器在近距离发出信号时,带有RFID的物品能自动返回其唯一的序列号,这样就能实现自动大批量辨识物品信息的工作。RFID技术解决了物品信息与互联网实现自动连接的问题,结合后续的大数据挖掘工作,能发挥其强大的威力。
在工业制造业里,传感器(Sensor)是另一类常见的大数据采集装置,它能将测量到的信息按一定规律变换为电信号输出,通常用于自动检测和控制等环节。传感器的种类极为丰富:大到机械设备、汽车、飞机、建筑物,小到一部智能手机、一个智能设备,都可以安装很多种传感器,传递温度、压力、位置、位移、光敏、距离、化学感应、生物、磁场等各类信号。未来携带传感器+大数据平台的智能设备将越来越多,基于传感器数据的大数据应用才刚刚起步,如智能医疗,智慧城市等,这方面有着广阔的前景。
3.3 数据存储技术的发展和演进
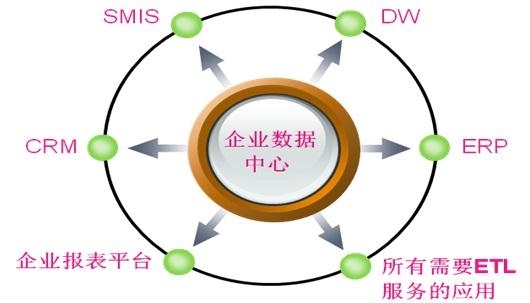
传统企业信息化系统采用关系数据库来进行数据存储,其中规模较大的通常被称为“数据集市”(Data Mart)。随着采集数据的种类越来越多,部分行业领先的公司看到了把不同数据集市集中到一个大系统中的价值,这个大系统称为企业级数据仓库(Enterprise Data Warehouse, EDW),由专门的数据团队(或称为数据中心)负责集中式的数据管理和维护。
图4:企业数据中心是各类数据业务的集中管理者
随着数据量的惊人增长,已经使用了20余年的传统数据库再也无法支撑起新的存储需求了,所以被Google称为Big Table和GFS的新型存储技术在过去的几年里被发明出来,并在行业中广泛应用,这些技术通过自动调配上万台服务器协同工作,能完成高性能和高可靠的数据存储任务,为大数据的运用铺平了道路。
3.4 云计算与大数据
云计算可谓是大数据的最好载体。由于大数据存储和运算非常复杂,传统企业在运作时需要投入很高的人力物力,因此把涉及存储运算的基础设施抽象和独立出来,形成的专门性服务称为云计算(Cloud Computing)。云计算就好比大数据时代的“电”,大数据系统则是“家用电器”——云计算注重服务的通用性,大数据关注实际的用途和效果。
云计算服务分为两大类:公有云和私有云。公有云是在开放网络中为客户提供服务,用户并不完全拥有云资源。私有云是为特定客户单独使用而构建的,独占使用的服务资源。使用公有云,相当于通过一根电线接入供电网;使用私有云,相当于在家里安装了一台发电机。
云计算的出现大大降低了大数据应用的门槛,未来无论是企业还是个人应用,采用云计算作为载体,大数据作为上层应用的方式将是最优的发展方向。
3.5 大数据挖掘原理和技术生态
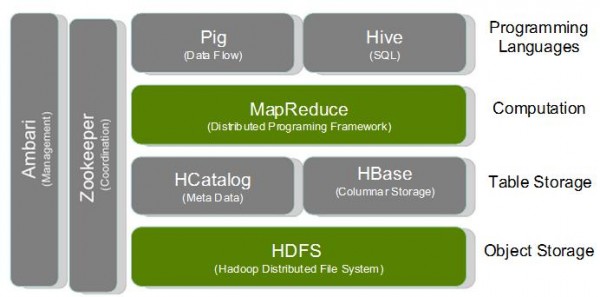
在解决了大数据采集、存储的问题后,最重要的环节是大数据挖掘技术。着名的Map-Reduce的计算框架很好的解决了大数据挖掘的性能问题,被产业界广泛使用,基于Map-Reduce原理最为知名的开源实现方案称为Hadoop。
在Map-Reduce基础上,近1-2年来一些新的流式计算技术也被国际知名公司和大学提出,例如twitter提出的Storm,Yahoo的S4,UC Berkeley的Spark,斯坦福大学的Phoenix等新技术。围绕这些核心的挖掘平台,现在已经形成了一整套大数据挖掘技术生态,为上层的数据应用奠定了基础。
图5:大数据运算平台常见的技术生态系统
3.6 数据类型与常见应用
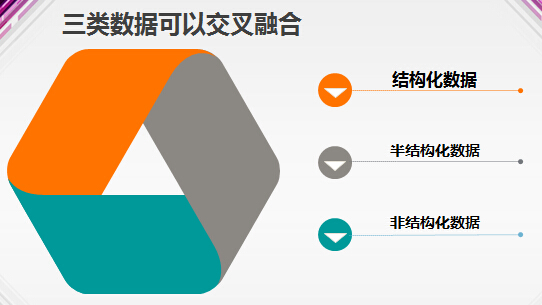
大数据挖掘应用中最常见的数据类型称为结构化数据,定义为存储在数据库里,能用二维表结构来逻辑表达实现的数据。结构化数据常用于记录生产、业务、交易、客户信息等方面的数据,这些数据规模较小,内容规范,含义明确,处理方式成熟,可以方便的产生各类数据报表,为企业运作提供最直接的依据。
以典型的制造型企业运作为例,其资产负债表、现金流表等核心财务报表,均出自于结构化数据的统计分析;其业务相关的库存、销量、分品类货物流转等数据,也通过类似的方式来产生。
如果是面向互联网业务的新型企业,则会更关注诸如网站的流量、移动APP的日活跃用户数(DAU,Daily Active Users)、登录用户数、停留时间等数据,这类数据统计则很多来源于半结构化数据,网络访问日志就是典型的一种半结构化数据。半结构化数据具有可被理解的逻辑流程和格式,但这些格式并不是用户友好的,有价值的信息参杂在大量的噪声和无用的数据中,分析起来比结构化数据复杂。
图6:大数据处理的三类数据交叉融合
比半结构化数据更复杂的是非结构化数据。文本信息是目前已记录的数量最为庞大的数据形式,例如网页中的文字内容、聊天记录、电子邮件,企业的各类文档等,它们包含了大量有价值的信息,对它们的分析处理催生出了自然语言处理(NLP , Natural Language Processing)这样专门的计算机学科。
大数据处理难度最高的是多媒体类的非结构化数据,包括图像、语音、视频等,对这些数据的深入挖掘和理解,能产生非常多新颖实用的功能,如自动监控、人脸识别、自动驾驶等。近年来Google、Facebook等公司积极进行深度学习(Deep Learning)相关技术的研发,用大规模机器学习的技术来解读多媒体的数据,已经取得了非常可观的进步。(陈运文博士)
图7:多媒体类的非结构化数据的处理能产生非常多新颖的功能
对各种类似数据的挖掘和处理还远没有结束,存在巨大的应用潜力。相信大数据系统在不久的将来能产生越来越多令人惊叹的功能,甚至改变大量产业的形态。
第四十一届CIO班招生
国际CIO认证培训
首席数据官(CDO)认证培训
责编:pingxiaoli
免责声明:本网站(http://www.ciotimes.com/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等)版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。