【干货】数据挖掘必须要具备知识结构类型
【干货】数据挖掘必须要具备知识结构类型
2016-01-13 14:40:04 来源:36大数据 抢沙发
抢沙发
2016-01-13 14:40:04 来源:36大数据
摘要:概念 类描述就是通过对某类对象关联数据的汇总,分析和比较,用汇总的简洁的精确的方式对此类对象的内涵进行描述,并概括这类对象的有关特征。
关键词:
大数据
四、聚类分析
与分类技术不同,在机器学习中,聚类是一种无指导学习。也就是说,聚类分析是在预先不知道欲划分类的情况下,根据信息相似度原则进行信息集聚的一种方法。聚类的目的是使得属于同一类别的个体之间的差别尽可能的小,而不同类别上的个体见的差别尽可能的大。因此,聚类的意义就在于将观察到的内容组织成类分层结构,把类似的事物组织在一起。通过聚类,人们能够识别密集的和稀疏的区域,因而发现全局的分布模式,以及数据属性之间的有趣的关系。(十一城注:聚类和分类的区别在于聚类是无监督学习,分类是有监督学习。聚类其实也可以理解为是一种分类,只是它这种分类)
数据聚类分析是一个正在蓬勃发展的领域。聚类技术主要是以统计方法、机器学习、神经网络等方法为基础。比较有代表性的聚类技术是基于几何距离的聚类方法,如欧氏距离、曼哈坦(Manhattan)距离、明考斯基(Minkowski)距离等。
聚类分析广泛应用于商业、生物、地理、网络服务等多种领域。例如,聚类可以帮助市场分析人员从客户基本库中发现不同的客户群,并能用不同的购买模式来刻画不同的客户群的特征,如图2-6显示了一个城市内顾客位置的二维图,数据点的三个簇是显而易见的。聚类还可以从地球观测数据库中帮助识别具有相似土地使用情况的区域;以及可以帮助分类识别互联网上的文档以便进行信息发现等等。
五、预测
预测型知识(Prediction)是指由历史的和当前的数据产生的并能推测未来数据趋势的知识。这类知识可以被认为是以时间为关键属性的关联知识,因此上面介绍的关联知识挖掘方法可以应用到以时间为关键属性的源数据挖掘中。
前面介绍分类知识挖掘时曾经提到过:分类通常用来预测对象的类标号。然而,在某些应用中,人们可能希望预测某些遗漏的或不知道的数据值,而不是类标号。当被预测的值是数值数据时,通常称之为预测。
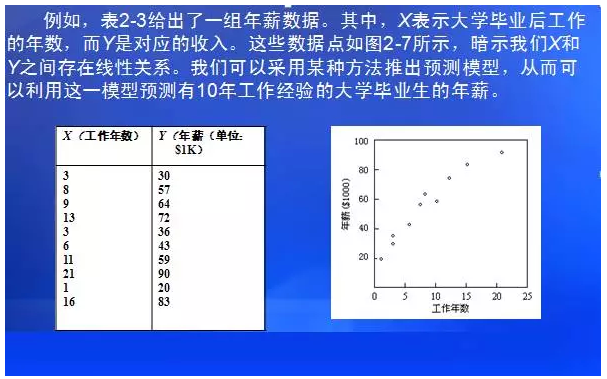
也就是说,预测用于预测数据对象的连续取值,如:可以构造一个分类模型来对银行贷款进行风险评估(安全或危险);也可建立一个预测模型以利用顾客收入与职业(参数)预测其可能用于购买计算机设备的支出大小
预测型知识的挖掘可以利用统计学中的回归方法,通过历史数据直接产生连续的对未来数据的预测值;可以借助于经典的统计方法、神经网络和机器学习等技术。无论如何,经典的统计学方法是挖掘预测知识的基础。
第四十一届CIO班招生
国际CIO认证培训
首席数据官(CDO)认证培训
责编:pingxiaoli
免责声明:本网站(http://www.ciotimes.com/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等)版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。