
2月24日,浙江工业大学计算机科学技术学院与软件学院院长、博导王万良在CIO时代APP微讲座栏目作了题为《深度学习的最新进展》的主题分享,对深度学习进行了详细的介绍。
 一、深度学习的兴起
一、深度学习的兴起
众所周知,深度学习是相对浅层学习而言的,已有的浅层学习包括神经网络ANN、SVM、Boosting、最大熵方法等等,其主要局限性在于深度的有限性,表示的学习能力也是有限的,如果要有一定深度,便会产生一系列问题,尤其是反馈到最后的误差很小,对神经网络参数的调整能力变得很弱。因此,引进了深度学习来克服这一系列问题。
1.深度学习的机理
深度学习最主要解决的便是特征表达问题,由于一般的学习方法中的特征提取均为人工手动进行的,而深度学习是直接面向数据的,特征表达由学习自动完成,包括预处理、特征提取、特征选择。最后与其他学习算法相同,能进行机器学习算法,包括推理、预测、识别等等。因此,深度学习有一个良好的特征表达,这也是深度学习识别成功的关键。相对于传统的做法,对特征可自动进行分类。深度学习的机理是基于人对视觉信息的了解。
1981年,诺贝尔医学奖获得者美国神经生物学家DavidHubel和TorstenWiesel发现:人的视觉系统的信息处理不是整体处理的,而是分级处理的。高层的特征是底层特征的组合,从低层到高层的特征表示越来越抽象,越能越来表现语义或意图,这便是深度学习的思想。抽象层面越高,存在的可能猜测就越少,便越利于分类。
2.深度学习的推动
首先是在2006年,加拿大多伦多大学教授Geoffrey Henton和他的学生在Science上发表的文章掀起了深度学习的浪潮,即提出理论。
2012年,Hinton组参加计算机视觉系统识别项目ImageNet使用CNN模型以超过第二名10个百分点的成绩夺取当年竞赛冠军,并引起了广泛注意。
尤其是伴随着未来云计算、大数据时代的到来,计算机能力的大幅提升,使得深度学习模型在计算机视觉、自然语言处理以及语音识别等众多领域都取得了较大成功。有专家预测,深度学习将在信息检索上取得重大的突破。
3.深度学习的基本思想
假设系统S有n层(S1,…,Sn),它的输入是I,输出是O,表示为:I=>S1=>S2=>……=>Sn=>O。如果调整系统中参数,使得它的输出O等于输出I,那么就可以自动地获得输入I的一系列层次特征,即S1,…,Sn。通过这种方式,便可以实现对输入信息进行分级表达了。其优点为可通过学习一种深层非线性神经网络结构,实现复杂函数的逼近,表征输入数据分布式表示。
目前,深度学习不仅在学术界,而且在产业界受到重视,这是至此深度学习最重要的一个特征。在学术界如计算机视觉、自然语言处理、机器学习、顶级期刊会议、公开课程代码等等;但推动机器学习发展重要的一个推手便是产业,如GoogleBrain、21世纪计算大会、百度IDL、“中国大脑”、刷脸支付等等,这些均促进了深度学习进一步的发展。
二、重要模型
具体如上图所示,
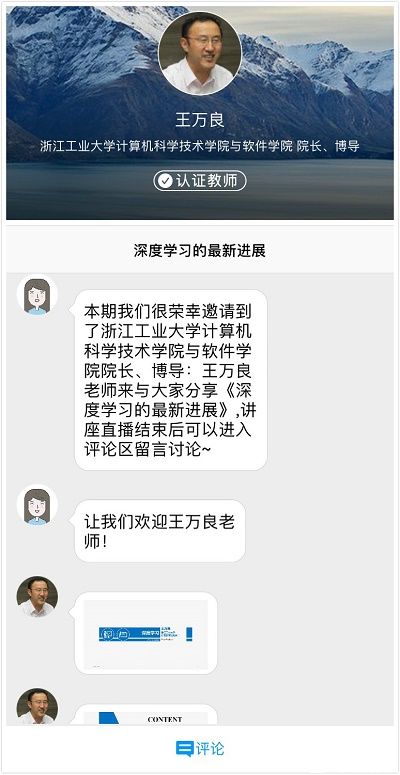
1.受限玻尔兹曼机
玻尔兹曼机是一种随机的递归神经网络,由二值神经元构成,每个神经元只取0和1两种状态。然而,即使使用模拟退火算法,这个网络的学习过程也非常慢。Hinton在原来的基础上去掉了玻尔兹曼机同层之间的连接,从而大大提高了学习效率。同时还有深度玻尔兹曼机、深度置信网络等,这些网络主要是将一些相互间的连接去掉。因此,它是由多层RBM堆叠而成的,神经元可以分成显性神经元和隐性神经元,显性神经元用于接受输入,隐性神经元用以提取特征。
2.卷积神经网络

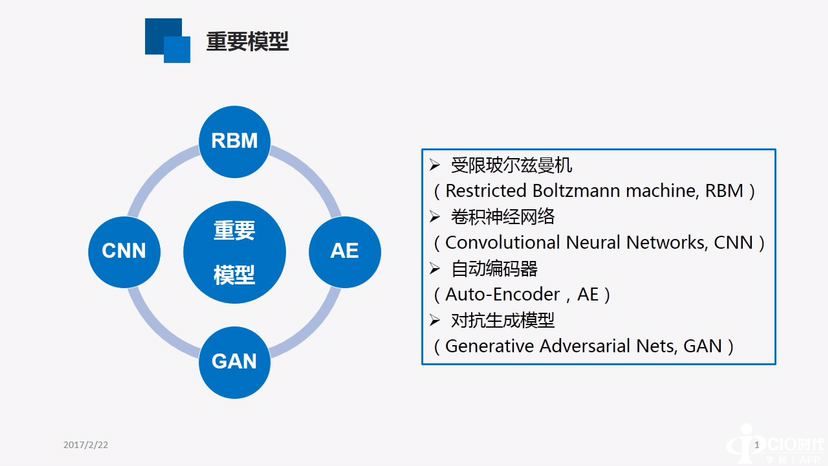
其核心便是卷积,其中有很多参数,使得训练变得非常复杂,根据数据机理进行简化,尤其是采用了局部感受野、权值共享以及时间或空间将采样的结构思想,使得网络中自由训练参数的个数大大减少,降低了网络参数选择的复杂度,但其基本原理仍为基于人或动物的视觉特征。
其中一个很重要的技术便是局部连接,上图为全连接神经网络图,每一个神经元的图像数据均有连接,其权值很多,根据视觉机理,眼睛所看到的不是全部,而仅为图像的某一部分,对每一部分用神经元连接,需要训练的权值便减少了很多。但仍有很多。根据视觉机理,每个局部的感受都是相同的。因此,可将每个神经元与局部图像连接时使用相同的权值,权值便大幅度下降,以及权值共享。
3.自动编码器
自动编码器(Auto-Encoder,AE)是一种尽可能复现输入信号的神经网络。我们构造一个神经网络,如果调整神经网络的权值使得输出与输入相同,中间的神经元表示的是对原来信号的一种压缩和编码,AE能找到可以代表原信息的主要成分,是一种非监督式的学习方法。
为提高编码器的性能,又提出了自动编码器的进步改进——稀疏自动编码器。稀疏自动编码器(Sparse Auto Encoder)是在自动编码器的基础上加上稀疏性约束,即约束每一层中的大部分节点都要为0,只有少数不为0。限制每一次得到的特征表达尽量稀疏,这样便可以简洁的表示原信息的主要成分。
降噪自动编码器(Denoising AutoEncoders,DA)是在自动编码器的基础上,在训练数据中加入噪声,让自动编码器学习去除这种噪声而获得实际输入。这就迫使编码器去学习输入信号的更加鲁棒的表达,这也是它的泛化能力比一般编码器强的原因。
4.生成对抗网络
基本思想为在一个神经网络中包含了一对相互对抗的模型:一个是生成网络G,用于逼近真实数据分布;另一个是判别网络D,辨别样本来自真实数据集还是生成网络G。两者均可以是非线性函数。如多层感知机。G的目的是使生成的数据能以假乱真,而D的目的则是正确区分真假数据。D的存在使得G无需真实数据的先验知识或复杂建模也能学习逼近真实数据,当D无法判断G的生成数据时,G和D达到纳什均衡。
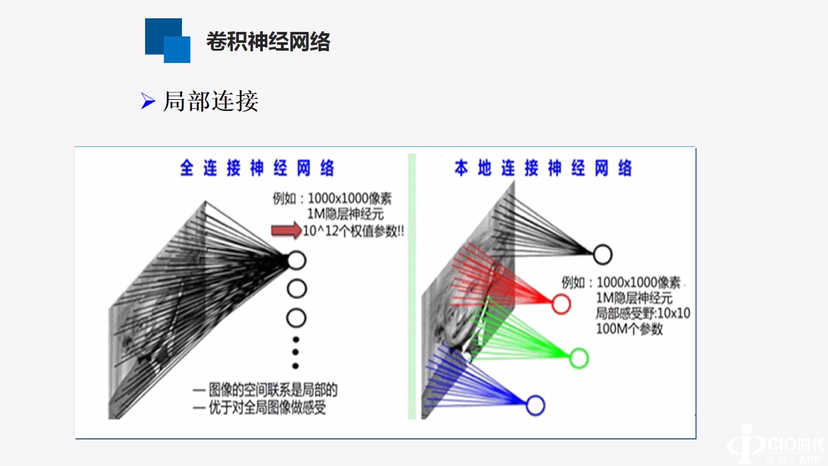
三、深度学习的应用
具体应用如上图所示,但不局限于这些方面。如语音识别合成、计算机视觉、大数据分析、自然语言处理等等。大数据不是一个新的内容,数据处理技术很便就存在,人们利用大数据技术获得了很多信息。但目前的数据很多很复杂,因此,目前的大数据问题更突出、更难用、更有用。而深度学习也是大数据分析的一个主要工具。
更突出:物联网的发展使数据越来越大,越来越复杂。数据量在2010年,全球便进入ZB年代(十万亿亿字节),2011年数据进入1.8ZB,2020年物联网数据增量达到40ZB左右。直观来看,近两年产生的数据总量相当于人类有史以来的总和,因此,数据量大更加突出。
更难用:原先的机理分析、统计不再适用,更多地依靠相关性分析。舍恩伯格的《大数据时代》:我们没有必要非得知道现象背后的原因,而是要让数据自己发声。数据的相关关系能够帮助我们更好地了解这个世界。
更有用:应为关系国际民生的内容。2015年的悉尼思想领袖峰会上,物联网之父凯文·艾希顿说:哪些智能酒瓶、智能比基尼、智能水杯什么的,都是渣渣。多做一些如城市大数据的智慧服务、工业大数据等等。
1.图像分类
在每个测试图像下写上正确的标签进行分类,显著的例子便是大规模视觉识别挑战赛,在此过程中首次应用卷积神经网络取得最好的效果,识别量大幅度降低,在未来的工作中始终保持领先地位。
2.视频跟踪
利用深度学习跟踪人物的轨迹,如跟踪人脸、跟踪汽车均取得了很好的效果。
3.生成对抗网络应用
如从文字描述生成图片、视频分析、将2D图像映射为3D形状、矢量空间运算等等。近期的研究是将生成对抗网络用于医药研究领域。莫斯科物理科技学院(MIPT),首次将GAN应用在研发具有特定医疗属性的药物(如抗癌药物等)。
四、展望
几个重要的研究方向:大数据深度学习、认知神经网络、复杂神经网络实现、无标签数据的特征学习。总之,人工智能的发展已不是云遮雾障,而是迎来产业发展的黄金期,前途十分光明。
第三十八届CIO班招生
国际CIO认证培训
首席数据官(CDO)认证培训
责编:houlimin
免责声明:本网站(http://www.ciotimes.com/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等)版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。




