作为一个开源云计算平台,Hadoop正受到越来越多开发者的重视。从企业的角度来说,日益增长的信息已经很难存储在标准关系型数据库甚至数据仓库
在本次公开课上,中科院计算所副研究员查礼博士做了主题演讲,解密了基于Hadoop的大规模数据处理系统的组成及原理。
hadoop.tmp.dir配置为你想要的路径,${user.name}会自动扩展为运行hadoop的代码
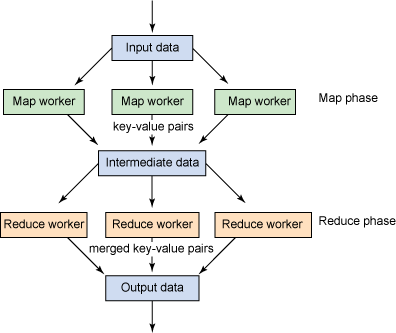
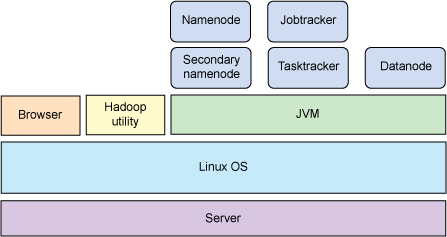
让我们开始简要介绍一下 map 和 reduce(从功能的角度考虑),然后再进一步钻研 Hadoop 编程模型及其体系结构和用来雕刻、分配、管理工作的元素。
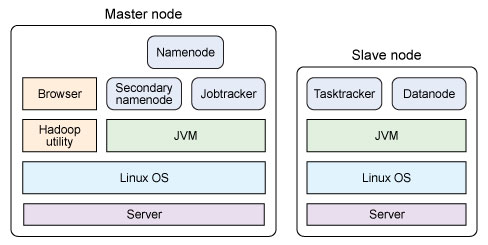
Hadoop 分布式计算架构的真正实力在于其分布性。换句话说,向工作并行分布多个节点的能力使 Hadoop 能够应用于大型基础设施以及大量数据的处理。
尽管 Hadoop 是一些大型搜索引擎数据缩减功能的核心部分,但是它实际上是一个分布式数据处理框架。搜索引擎需要收集数据,而且是数量极大的数据。
在讲座中,Milind Bhandarkar给与会者讲述了Hadoop一些最重要的参数的配置方法以及这些参数对系统的性能有何影响。
在经历了长达25年的统治地位后,关系型数据库正面临越来越火的“NoSQL”挑战,而挑战者是以Hadoop为代表的分布式计算开源架构。
据国外媒体报道,Cloudera日前从Meritech Capital获得2500万美金融资,加上前投资人Accel和Greylock公司的融资,Cloudera将拥有超过3600万美金的现金。
日前,雅虎宣布新增斯坦福大学,华盛顿大学,密歇根大学,普渡大学加入到Hadoop集群计算研究中。