Spark的误解-不仅Spark是内存计算,Hadoop也是内存计算
Spark的误解-不仅Spark是内存计算,Hadoop也是内存计算
2018-05-11 09:47:29 来源:intsmaze-刘洋 抢沙发
抢沙发
2018-05-11 09:47:29 来源:intsmaze-刘洋
摘要:市面上有一些初学者的误解,他们拿Spark和Hadoop比较时就会说,Spark是内存计算,内存计算是Spark的特性。请问在计算机领域,MySQL,Redis,SSH框架等等他们不是内存计算吗?依据冯诺依曼体系结构,有什么技术的程序不是在内存中运行,需要数据从硬盘中拉取,然后供CPU进行执行?
关键词:
Hadoop
Spark
市面上有一些初学者的误解,他们拿Spark和Hadoop比较时就会说,Spark是内存计算,内存计算是Spark的特性。请问在计算机领域,MySQL,Redis,SSH框架等等他们不是内存计算吗?依据冯诺依曼体系结构,有什么技术的程序不是在内存中运行,需要数据从硬盘中拉取,然后供CPU进行执行?所有说Spark的特点是内存计算相当于什么都没有说。
那么Spark的真正特点是什么?抛开Spark的执行模型的方式,它的特点无非就是多个任务之间数据通信不需要借助硬盘而是通过内存,大大提高了程序的执行效率。而Hadoop由于本身的模型特点,多个任务之间数据通信是必须借助硬盘落地的。那么Spark的特点就是数据交互不会走硬盘。只能说多个任务的数据交互不走硬盘,但是Spark的shuffle过程和Hadoop一样仍然必须走硬盘的。
 误解一:Spark是一种内存技术
误解一:Spark是一种内存技术
大家对Spark最大的误解就是spark一种内存技术。其实没有一个Spark开发者正式说明这个,这是对Spark计算过程的误解。Spark是内存计算没有错误,但是这并不是它的特性,只是很多专家在介绍spark的特性时,简化后就成了spark是内存计算。
什么样是内存技术?就是允许你将数据持久化在RAM中并有效处理的技术。然而Spark并不具备将数据数据存储在RAM的选项,虽然我们都知道可以将数据存储在HDFS, HBase等系统中,但是不管是将数据存储在磁盘还是内存,都没有内置的持久化代码。它所能做的事就是缓存数据,而这个并不是数据持久化。已经缓存的数据可以很容易地被删除,并且在后期需要时重新计算。
但是有人还是会认为Spark就是一种基于内存的技术,因为Spark是在内存中处理数据的。这当然是对的,因为我们无法使用其他方式来处理数据。操作系统中的API都只能让你把数据从块设备加载到内存,然后计算完的结果再存储到块设备中。我们无法直接在HDD设备上计算;所以现代系统中的所有处理基本上都是在内存中进行的。
然Spark允许我们使用内存缓存以及LRU替换规则,但是你想想现在的RDBMS系统,比如Oracle ,你认为它们是如何处理数据的?它们使用共享内存段作为table pages的存储池,所有的数据读取以及写入都是通过这个池的,这个存储池同样支持LRU替换规则;所有现代的数据库同样可以通过LRU策略来满足大多数需求。但是为什么我们并没有把Oracle 称作是基于内存的解决方案呢?再想想操作系统IO,你知道吗?所有的IO操作也是会用到LRU缓存技术的。
Spark在内存中处理所有的操作吗?Spark的核心:shuffle,其就是将数据写入到磁盘的。shuffle的处理包括两个阶段:map 和 reduce。Map操作仅仅根据key计算其哈希值,并将数据存放到本地文件系统的不同文件中,文件的个数通常是reduce端分区的个数;Reduce端会从 Map端拉取数据,并将这些数据合并到新的分区中。所有如果你的RDD有M个分区,然后你将其转换成N个分区的PairRDD,那么在shuffle阶段将会创建 M*N 个文件!虽然目前有些优化策略可以减少创建文件的个数,但这仍然无法改变每次进行shuffle操作的时候你需要将数据先写入到磁盘的事实!
所以结论是:Spark并不是基于内存的技术!它其实是一种可以有效地使用内存LRU策略的技术。
误解二:Spark要比Hadoop快 10x-100x
大家在Spark的官网肯定看到了如下所示的图片
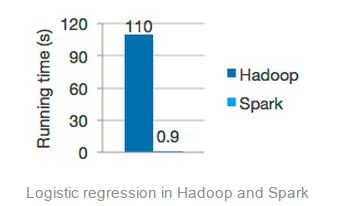
这个图片是分别使用 Spark 和 Hadoop 运行逻辑回归(Logistic Regression)机器学习算法的运行时间比较,从上图可以看出Spark的运行速度明显比Hadoop快上百倍!但是实际上是这样的吗?大多数机器学习算法的核心部分是什么?其实就是对同一份数据集进行相同的迭代计算,而这个地方正是Spark的LRU算法所骄傲的地方。当你多次扫描相同的数据集时,你只需要在首次访问时加载它到内存,后面的访问直接从内存中获取即可。这个功能非常的棒!但是很遗憾的是,官方在使用Hadoop运行逻辑回归的时候很大可能没有使用到HDFS的缓存功能,而是采用极端的情况。如果在Hadoop中运行逻辑回归的时候采用到HDFS缓存功能,其表现很可能只会比Spark差3x-4x,而不是上图所展示的一样。
根据经验,企业所做出的基准测试报告一般都是不可信的!一般独立的第三方基准测试报告是比较可信的,比如:TPC-H。他们的基准测试报告一般会覆盖绝大部分场景,以便真实地展示结果。
一般来说,Spark比MapReduce运行速度快的原因主要有以下几点:
task启动时间比较快,Spark是fork出线程;而MR是启动一个新的进程;
更快的shuffles,Spark只有在shuffle的时候才会将数据放在磁盘,而MR却不是。
更快的工作流:典型的MR工作流是由很多MR作业组成的,他们之间的数据交互需要把数据持久化到磁盘才可以;而Spark支持DAG以及pipelining,在没有遇到shuffle完全可以不把数据缓存到磁盘。
缓存:虽然目前HDFS也支持缓存,但是一般来说,Spark的缓存功能更加高效,特别是在SparkSQL中,我们可以将数据以列式的形式储存在内存中。
所有的这些原因才使得Spark相比Hadoop拥有更好的性能表现;在比较短的作业确实能快上100倍,但是在真实的生产环境下,一般只会快 2.5x ~ 3x!
第三十五届CIO班招生
国际CIO认证培训
首席数据官(CDO)认证培训
责编:zhangxuefeng
免责声明:本网站(http://www.ciotimes.com/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等)版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。




