大数据之谜Spark基础篇,核心RDD特征分析讲解
大数据之谜Spark基础篇,核心RDD特征分析讲解
2018-04-19 09:36:28 来源:大数据之谜 抢沙发
抢沙发
2018-04-19 09:36:28 来源:大数据之谜
摘要:RDD(Resilient Distributed Datasets)弹性分布式数据集,是分布式内存的一个抽象概念。我们可以抽象的代表对应一个HDFS上的文件,但是他实际上是被分区的,分为多个分区撒落在Spark集群中的不同节点上。
关键词:
大数据
Spark
RDD特征概要总结:
a、RDD是Spark提供的核心抽象,全称为Resillient Distributed Dataset,即弹性分布式数据集。
b、RDD在抽象上来说是一种元素集合,包含了数据。它是被分区的,分为多个分区,每个分区分布在集群中的不同节点上,从而让RDD中的数据可以被并行操作。
c、RDD通常通过Hadoop上的文件,即HDFS文件或者Hive表,来进行创建;有时也可以通过应用程序中的集合来创建。
d、RDD最重要的特性就是,提供了容错性,可以自动从节点失败中恢复过来。即如果某个节点上的RDD partition,因为节点故障,导致数据丢了,那么RDD会自动通过自己的数据来源重新计算该partition。这一切对使用者是透明的。
e、RDD的数据默认情况下存放在内存中的,但是在内存资源不足时,Spark会自动将RDD数据写入磁盘。
下面我们一起来对其关键特征进行详细分析
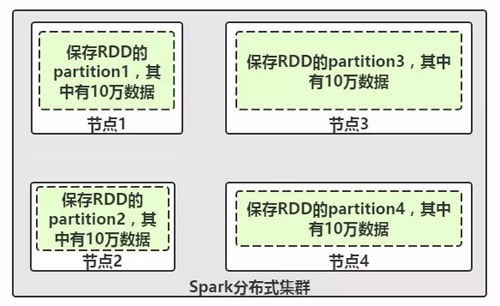
图1-RDD分布式特征
分析:
RDD(Resilient Distributed Datasets)弹性分布式数据集,是分布式内存的一个抽象概念。我们可以抽象的代表对应一个HDFS上的文件,但是他实际上是被分区的,分为多个分区撒落在Spark集群中的不同节点上。比如现在我们的一个RDD有40万条数据,并分为4个partition,这4个分区数据分别存储在集群中的节点1、2、3、4中,而每个partition分到10万条数据。如图1所示,这样的一个RDD将数据分布式撒落在集群的一批节点上,每个节点只是存储RDD的部分partition,这就是RDD的分布式结构模型。
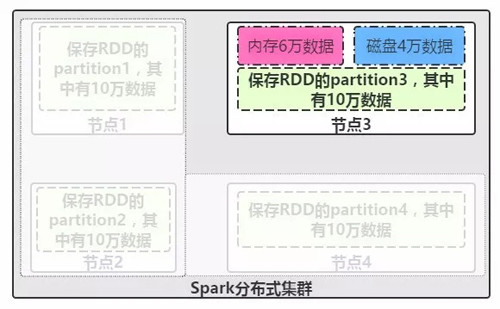
图2-RDD弹性式特征
分析:
RDD的弹性特征说明,当RDD的每个partition数据都存放到Spark集群节点上时候,默认是都存放在内存中的,但是如果内存放不下这么多的数据时,我们该怎么办呢?这时候RDD的弹性特征就表现出来了。如上图2所示,在节点3内存中最多只能存储6万数据,结果我们需要存放一个partition数据为10万,那么这时就得把partition中的剩余4万数据写入到磁盘上进行保存了。而这种存储的分配针对用户是透明的,我们不用管他怎么存储,虽然这种存储机制是有配置参数提供我们选择的,后续深入讲解时候会介绍到如何选择存储策略,这里就不加深难度了,所以,RDD的这种自动进行内存和磁盘之间权衡和却换的机制,就是RDD的弹性特征所在。
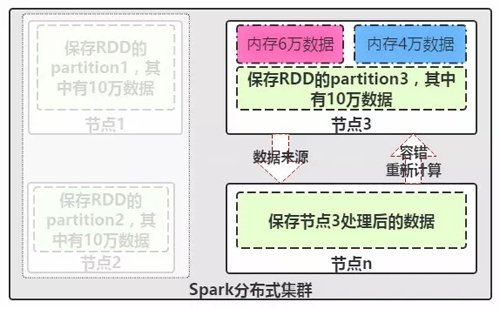
图3-RDD容错性特征
分析:
最后我们来看看RDD被分散的存放在集群的各个节点上了,那假如某个节点运行时候出现问题,数据该怎么办呢?这里Spark的RDD支持了强大的容错机制,如上图3,在运行节点n时候出现了问题,这时候就需要重新获取数据进行计算,那RDD将启动容错机制,尝试寻找上游依赖数据源节点3来重新获取数据进行计算,这里深入分析将会提出另外一个概念来了,那就是DAG(有向无环图)、进一步了解RDD的依赖关系,与底层逻辑关系了,期待分析的时候您能光临。
第三十五届CIO班招生
国际CIO认证培训
首席数据官(CDO)认证培训
责编:zhangxuefeng
免责声明:本网站(http://www.ciotimes.com/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等)版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。




