大数据和云计算的冲突
大数据和云计算的冲突
2018-01-05 09:22:51 来源:企业网D1Net 抢沙发
抢沙发
2018-01-05 09:22:51 来源:企业网D1Net
摘要:无论如何,所有IT都有两个核心要素:数据与数据的逻辑。每个使用大数据的人都知道:要使用大量的数据,首先需要对数据进行处理,而其处理都会产生一个传输瓶颈,并严重影响其性能,并且这种逻辑的任何功能都变成纯粹的理论。
关键词:
大数据
云计算
最近,IT行业专家在参加相关会议时发现了一个隐藏的主题,那就是虽然很多人将关注的重点转移到基于云计算的架构(混合云)以及所需要的云管理平台,但会议的报告表明,很多人都承认并没有密切关注全球数字数据量的巨大增长。
存储供应商PureStorage公司的演讲报告引用了其他两家供应商的两个数据点:首先,思科公司2017年6月发布的白皮书“Zettabyte时代:趋势与分析”推断了互联网带宽的增长。其次是由希捷公司委托IDC公司进行研究的调查报告“数据时代2025”推测了全球数据增长的趋势。PureStorage公司结合了这两家公司的推断,得出了结论。如下图所示。
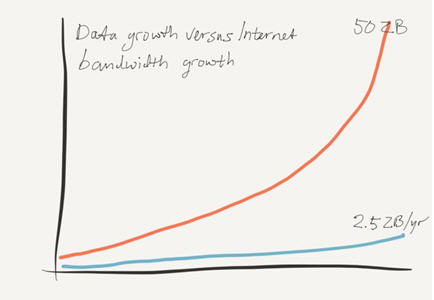
PureStorage公司的报告描述了全球数据增长和全球互联网带宽增长之间的冲突
如果这些趋势成为现实,并且有足够的理由认为这些预测是合理的,那么这些趋势将在未来几年对计算和数据格局产生重大影响。并将对云计算的应用产生特别的影响。注意:云计算是真实的,将成为未来IT环境的重要组成部分,但是IT部门认为它是一种灵丹妙药这种简单化的想法,会让人想起当初网络热潮的破灭。而人们知道将会有什么样的结果。
不能回避的问题
无论如何,所有IT都有两个核心要素:数据与数据的逻辑。每个使用大数据的人都知道:要使用大量的数据,首先需要对数据进行处理,而其处理都会产生一个传输瓶颈,并严重影响其性能,并且这种逻辑的任何功能都变成纯粹的理论。
即使有少量的数据,这也可能是因为延迟而发生。例如,企业将其应用程序服务器迁移到云端,同时将数据库服务器保留在本地,这可能在理论上可行,但是当应用程序对数据库与数据库之间的网络延迟敏感时,就根本不起作用。对于少量的数据来说,情况就是如此。这就是为什么许多组织都在尝试调整软件的原因,使其对延迟的敏感度降低,从而能够进入云端。但是,如果数据量很大,则需要将数据处理和数据彼此靠近,否则就无法工作。企业增加对大量并行性的需求来处理这些数据,并获得Hadoop和其他处理大量数据问题的体系结构。
现在,全球的数据量呈指数增长。如果IDC公司的推测成为事实的话,那么在几年的时间里,全世界将存储大约50ZB的数据。另一方面,虽然互联网传输数据的总容量也在增长,但增长速度更为缓慢。在全球数据量增长到50ZB的同一时期,互联网总带宽将达到每年2.5ZB(如果思科的推断成为事实的话)。
从这两个推断(并不是不合理的)中得出的结论是,全球可用的互联网带宽远远不能满足移动大量数据的需求。而且这也忽略了目前大约80%的带宽用于流媒体视频的事实。因此,即使企业已经针对核心应用程序中的延迟问题编写了代码,对于数据量较大的情况,也会出现带宽问题。
现在这个隐患实际上成为了一个问题吗?如果处理或使用这些数据在本地部署的数据中心发生的话,也就是说在同一个数据中心中存储数据。但是,一方面,数据量呈指数增长,另一方面,全球各行业也在积极寻求云战略,就是把将所有类型的工作负载都迁移到云端,即使是“无服务器”(例如,AWS Lambda),这样的做法也是绝对极端的。
假设只有小规模的结果(从庞大的数据集中计算出来)也许会有所帮助,因为大量数据的实际价值来自它们的结合。这可能意味着将来自不同所有者的数据(例如企业的客户记录与来自Twitter的数据)结合起来。而这所有不同的集合将会成为一个难题。
所以,人们看到的是两个相反的事态发展。一方面,人们都忙于适应基于云的体系结构,这种体系结构最终是基于分布式数据的分布式处理。另一方面,人们使用的数据量越来越大,必须将数据和处理整合到一个物理位置。
那么这意味着什么?
人们可以预期,Hadoop在应用程序架构层面所做的工作也将在全球范围内发生:庞大的数据集将成为使数据的逻辑具有意义的吸引力。而那些庞大的数据集将会被吸引到一起。
举个例子:许多公司现在都在努力减少移动数据的需求。因此,在物联网领域有很多关于边缘计算的讨论:本地处理传感器和其他物联网设备的数据。当然,这也意味着处理过程也必须是本地化的,可以放心地假设一下,企业不会在一组传感器中拥有同样的计算能力,而不是在大分析中可以做到的设置。或者:也许自主驾驶汽车的数据很可能不会再采用Hadoop集群,而可以通过这种方式来最小化数据流量,但以计算量为代价。
这个问题还有另一个解决方案:与数据中心结合在一起。数据中心托管提供商提供的服务正在崛起。他们提供具有优化内部流量功能的大型数据中心,云计算提供商和大型云用户的服务器都在一起。从逻辑上讲,用户的业务可能在云端,但实际上与云计算服务提供商在同一处所。
企业不仅想在AWS或Azure上运行其逻辑数据,也想在数据中心这样做,企业也有自己的私有数据湖,所以所有的数据都在本地处理,数据聚合也在本地。但是数据中心托管模式是另一种可能的解决方案,用于解决因数据呈指数级增长而带来的带宽和延迟问题。
情况可能不像那两个调查报告描述的那样可怕。例如,所有数据的实际平均波动率最终将非常低。另一方面,企业不希望在陈旧的数据上运行分析。但是可以得出一个结论:简单地假设企业可以将其工作负载分配给不同的云提供商是有风险的,尤其是如果同时处理的数据量(如果企业都想把他们自己的数据与来自Twitter、Facebook的数据流结合起来,那么更不用说这些组合产生了各种各样的新数据流)。
因此,企业对数据和处理的位置做出良好的战略设计决策是成功的关键。
第三十五届CIO班招生
国际CIO认证培训
首席数据官(CDO)认证培训
责编:zhangxuefeng
免责声明:本网站(http://www.ciotimes.com/)内容主要来自原创、合作媒体供稿和第三方投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
本网站刊载的所有内容(包括但不仅限文字、图片、LOGO、音频、视频、软件、程序等)版权归原作者所有。任何单位或个人认为本网站中的内容可能涉嫌侵犯其知识产权或存在不实内容时,请及时通知本站,予以删除。




