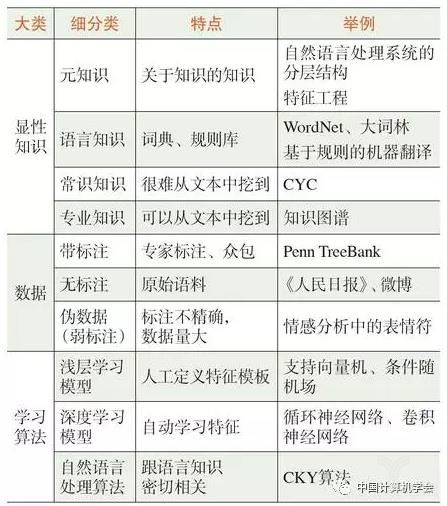
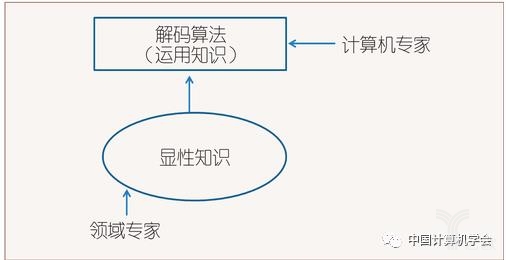
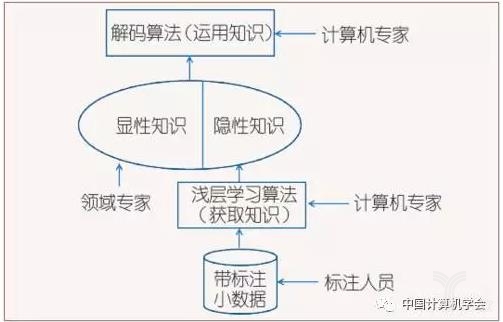
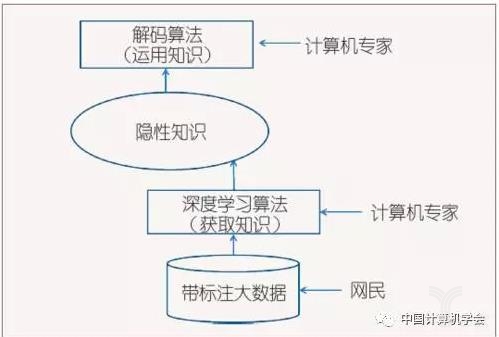
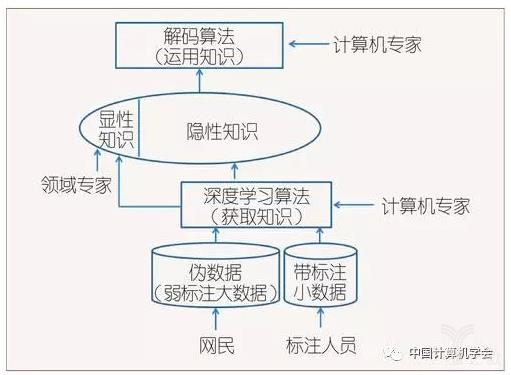
图1~4介绍了自然语言处理中知识获取方式演进的几个阶段。可以看到,真正的知识源是人。一共有三种人在提供知识:领域专家、标注人员和广大网民。其中标注人员包括专职的数据标注人员、兼职的学生,以及众包平台上的标注者。而计算机专家研制有关的算法,用算法从数据中获得隐性的知识。
图1所示的是专家系统时期,领域专家(主要是语言学家)直接提供显性知识。图2所示的是语料库方法占主导地位的时期。在语料库方法中,领域专家提供的元知识仍然起到重要作用,比如决定自然语言处理系统的分层结构,决定待识别对象的特征等。与专家通过内省方式编制的语言知识相比,标注人员标注的小规模数据中所蕴含的知识更全面、更精确、更加量化。
深度学习“端到端”的方法兴起后,有些简单问题,如果能够找到足够多的大数据,则会按照图3的模式获取知识,即显性知识完全退场。深度学习系统几乎不需要领域专家提供的元知识,由机器自己确定特征,并分配各层的功能,尽管这些功能的划分是隐性的,难以解释的。
但是,对很多问题而言,带标注数据是有限的,甚至是很有限的,因此图3所示的理想情况并不多。图4是比较现实的解决方案:将大规模“伪数据”与人工标注的小数据结合在一起,同时接受领域专家提供的部分元知识,如此,在数据不充分的情况下,借助人工的力量,追求最优的系统性能。
我们在回顾自然语言处理的发展历程时可以看到,知识的获取方式在不断地演进:从以专家内省方式获取专家知识,到由专人标注小规模数据集,这一步演进使自然语言处理摆脱了对个别专家有限经验的依赖;从专人标注到吸引众多网民开展的“众包”,又使标注成本降低,范围拓展,规模扩大。
但“众包”毕竟需要研究者主动去找一些人来有意识地给一批数据打标签,由于成本的原因,数据规模还是受到限制。于是又有了“自然标注大数据”的出现,即利用人们在使用互联网时不自觉地留下的记录,获取数据的标签。
例如,一个博客作者在提交一篇博文时,该作者为了让自己的博文更易于被读者检索而打上标签,客观上机器就可以利用这个标签作为博文分类或关键词抽取的依据。总之,在自然语言处理领域,知识的获取就是沿着不断降低成本、扩大规模,从人工到自动,从专人标注到群体智慧的路线演进着,自然语言处理可以利用的知识越来越丰富了。
四、大数据与深度学习相互配合,推动自然语言处理的发展
自然语言处理系统的关键是知识的获取。在知识获取的三个要素中,至少要有一个有所提高、有所突破,才能够带来自然语言处理整体系统性能的提高。换句话说,如果没有新知识、新数据、新算法加入到自然语言处理系统中,系统的能力是不会提升的。
近年来,在自然语言处理知识获取的三要素中,最主要的推动力量是哪一个呢?答案首先是数据,是用户在使用互联网、移动互联网的过程中贡献出来的富含群体智慧的大数据;其次是深度学习,深度学习使大数据的潜力得到充分释放。
可以说,是“大数据+深度学习”推动了这一波自然语言处理的热潮。显性知识的贡献主要体现在元知识和知识图谱上,传统手工构造的语言知识近年来发挥的作用很有限。
大数据和深度学习是相互依赖的:一方面,大数据需要复杂的学习模型。这一点之前是有争议的,有人认为有了大数据模型可以变得很简单,极端情况是有了全量数据后,就可以通过查表解决问题了。
但我们看到的事实是:对于大多数人工智能问题而言,数据量总是不够的,而且如果要细致地刻画大数据,尤其是长尾数据,就需要复杂模型,只有复杂模型才能够把大数据的沟沟坎坎描绘清楚,才能够把大数据的潜力充分发挥出来。
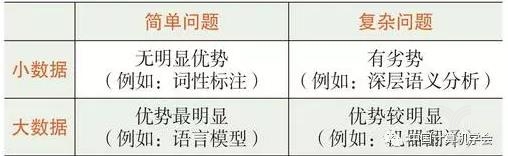
另一方面,深度学习需要大数据。深度学习不是万能的,在数据不足时,其效果将大打折扣。如表2所示,深度学习在获得大规模训练数据的简单问题上优势最明显。对于比较复杂的问题,例如机器翻译,如果有充足的双语对齐语料(如中英之间),则能取得较为明显的进展。这两年,神经网络机器翻译(NMT)已经迅速超越统计机器翻译(SMT)。但是,在人为定义的一些语言分析问题(如词性标注、深层语义分析)上,由于不可能获得充足的大数据,因而即便是针对简单问题,深度学习也没有明显超越传统方法,在复杂问题上甚至有劣势。因为问题复杂,而数据量不够时,学习工具越强大就越容易形成过拟合,所以效果自然不好。
表2深度学习用于自然语言处理问题的效果
从上述分析可以看出,一旦拥有大规模的训练数据,深度学习的威力是巨大的,可以在短时间内以摧枯拉朽的气势替代原有技术。这样的技术机会必须高度重视、尽力捕捉。需要强调的一点是,这里所谓“深度学习”的方法,关键在于“端到端”,即把从输入到输出的全部工作交给机器去处理,而不再人为地分层。下面试以“信息抽取”为例加以说明。信息抽取有两种做法:一是先做句法分析,再做信息抽取;二是直接做信息抽取,后者就是所谓的“端到端”。
在“端到端”的模型中,也是分层的,但是由机器自己去分层处理,各层的含义不是直观可以理解的。当用于端到端的训练数据不足时,就需要人为的帮助,比如把信息抽取的过程分成两步去做:第一步,先做出句法树(这一步增加了显性知识,但也引入了误差);第二步,实施信息抽取。当用于端到端的训练数据充足时,就可以一步到位——直接做信息抽取,而且性能更好。与信息抽取类似的还有情感二元分类、句间关系分类、问答对匹配等。
“端到端”方法取得的进步,甚至让人质疑,句法分析、语义分析这些人为定义的传统自然语言处理核心问题是否还有价值,是不是伪命题?我们的看法是:很多问题是复杂的,而且很难找到足够多的训练数据,因此人工显性知识,尤其是元知识(对句法树的定义本身也是显性元知识)的介入仍然是必要的。
五、结语
自然语言处理中的各类问题都可以抽象为:如何从形式与意义的多对多映射中,根据语境选择一种映射。要让机器破解形式与意义的多对多映射的困局,需要利用知识进行约束。知识获取的三要素是:显性知识、数据和学习算法。知识的获取正沿着不断降低成本、扩大规模,从手动到自动,从显性到隐性,从专人标注到伪数据的路线演进。
大数据的到来使深度神经网络有了用武之地。如果有足够多的大数据,端到端深度学习的方法能够使得自然语言处理系统的性能明显提升,但由于人工标注数据的成本很高,所以数据规模难以扩大。如何移植、采集、制造大规模“伪数据”,如何将大规模的伪数据与小规模的人工标注数据相结合,成为把深度学习应用于自然语言处理问题的重要研究内容,这一方法已经显示出强大的威力。